小説を読もうの累計ランキングをDoc2Vecで解析するの続き。
前回学習済みモデルによって小説間の類似度を見ることが出来た。今度はクラスタリングを行う。
前回のモデルを改善する
次に進む前に少しスクレイピングの処理を修正する。1から5話まで取得する様にしていたが、作品によって1話当たりの文字数にかなり差があるので、単語数を基準に本文を取得するように変更する。またサンプルをTop 100(これでもかなり少ない)まで増やす。
# 累計ランキングをTop100まで取得
def novel_total():
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
r = requests.get('http://yomou.syosetu.com/rank/list/type/total_total/', headers=headers, timeout=20)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text)
rank_index = soup.find_all('div', class_='rank_h')
sleep(1)
with open('drive/My Drive/Colab Notebooks/syosetu/novel_datas.txt', 'w') as f:
for rank in range(100):
link = rank_index[rank].find('a')
url = link.get('href')
title = link.get_text()
# 後でわかりやすいようにURLと小説のタイトルを設定
f.write('{0}\t{1}\t'.format(url, title))
print('rank:{0} title:{1}'.format(rank + 1, title))
chapter = 0
word_count = 0
while word_count < 5000 and chapter < 40:
# 単語が5000未満かつ、40話以下の間繰り返し取得する
try:
words = keitaiso(novel_text_dler('{0}{1}/'.format(url, chapter + 1)))
except (HTTPError, URLError) as e:
print(e)
break
except socket.timeout as e:
print(e)
continue
else:
f.write(words)
print('chapter:{0}'.format(chapter + 1))
word_count += len(words.split())
chapter += 1
f.write('\n')
モデルを作成するパラメーターも少し変更する。
# 学習の実行
m = Doc2Vec(documents=trainings, dm=1, vector_size=400, min_count=4, workers=4, epochs=40)
実行結果を確認する。
m = Doc2Vec.load('drive/My Drive/Colab Notebooks/syosetu/doc2vec.model')
# 0番目の小説に似ている小説は?(0番目の小説のタイトルは、「転生したらスライムだった件」)
print(m.docvecs.most_similar(0))
前回:
[(27, 0.3229605555534363), (11, 0.27810564637184143), (42, 0.24812708795070648), (13, 0.2365787774324417), (29, 0.22865955531597137), (33, 0.21636559069156647), (22, 0.19751328229904175), (20, 0.18333640694618225), (36, 0.1763637661933899), (25, 0.1638755202293396)]
今回:
[(27, 0.2789984941482544), (13, 0.26930510997772217), (60, 0.2584960460662842), (48, 0.25848516821861267), (68, 0.24882027506828308), (33, 0.24246476590633392), (49, 0.23103246092796326), (52, 0.22929105162620544), (94, 0.22420653700828552), (12, 0.22121790051460266)]
一番目が「27:モンスターがあふれる世界になったので、好きに生きたいと思います」であるのは変更なしであるが、二番目には「13:異世界のんびり農家」が出て来た。チートぐらいしか共通点はなさそう。試しにwindowをデフォルトの8から16に増やしてみる。
するとこのようになった。
[(60, 0.3200589418411255), (52, 0.3115108609199524), (27, 0.31150585412979126), (49, 0.2996276319026947), (13, 0.299365371465683), (18, 0.2926834225654602), (97, 0.2818679213523865), (12, 0.2745039761066437), (29, 0.2639138996601105), (68, 0.2628819942474365)]
一番目は「60:聖者無双 ~サラリーマン、異世界で生き残るために歩む道~」、二番目は「52:進化の実~知らないうちに勝ち組人生~」となった。今度は「残酷な描写あり」、「異世界」、「ハーレム」、「チート」と共通点は多そうなのでこちらを採用する。
クラスター分析する
今回も「Doc2Vecを使って小説家になろうで自分好みの小説を見つけたい話」を参考にさせて頂いた。
これらは便利な関数が用意されているので、それらに値を渡すだけでクラスタリングから図の作成まで行える。
import numpy as np
import matplotlib.pyplot as plt
from gensim.models.doc2vec import Doc2Vec
from scipy.cluster.hierarchy import linkage, fcluster, dendrogram
from matplotlib.font_manager import FontProperties
# 階層型クラスタリングの実施
def hierarchical_clustering(emb, threshold):
# ウォード法 x ユークリッド距離
linkage_result = linkage(emb, method='ward', metric='euclidean')
# クラスタ分けするしきい値を決める
threshold_distance = threshold * np.max(linkage_result[:, 2])
# クラスタリング結果の値を取得
clustered = fcluster(linkage_result, threshold_distance, criterion='distance')
print("end clustering.")
return linkage_result, threshold_distance, clustered
# 階層型クラスタリングの可視化
def plot_dendrogram(linkage_result, doc_labels, threshold):
fp = FontProperties(fname=r'drive/My Drive/Colab Notebooks/IPAexfont00301/ipaexg.ttf')
plt.figure(figsize=(16, 8), facecolor='w', edgecolor='k')
dendrogram(linkage_result, labels=doc_labels, color_threshold=threshold)
plt.title('Dendrogram', fontproperties=fp)
plt.xticks(fontsize=10)
print('end plot.')
plt.savefig('drive/My Drive/Colab Notebooks/syosetu/novel_hierarchy.png')
# 階層型クラスタリング結果の保存
def save_cluster(doc_index, clustered):
doc_cluster = np.array([doc_index, clustered])
doc_cluster = doc_cluster.T
doc_cluster = doc_cluster.astype(np.dtype(int).type)
doc_cluster = doc_cluster[np.argsort(doc_cluster[:, 1])]
np.savetxt('drive/My Drive/Colab Notebooks/syosetu/novel_cluster.csv', doc_cluster, delimiter=',', fmt='%.0f')
print('save cluster.')
m = Doc2Vec.load('drive/My Drive/Colab Notebooks/syosetu/doc2vec.model')
vectors_list = [m.docvecs[n] for n in range(len(m.docvecs))]
threshold = 0.8
linkage_result, threshold, clustered = hierarchical_clustering(emb=vectors_list, threshold=threshold)
plot_dendrogram(linkage_result=linkage_result, doc_labels=list(range(100)), threshold=threshold)
save_cluster(list(range(100)), clustered)
実行すると以下のような画像が表示される。
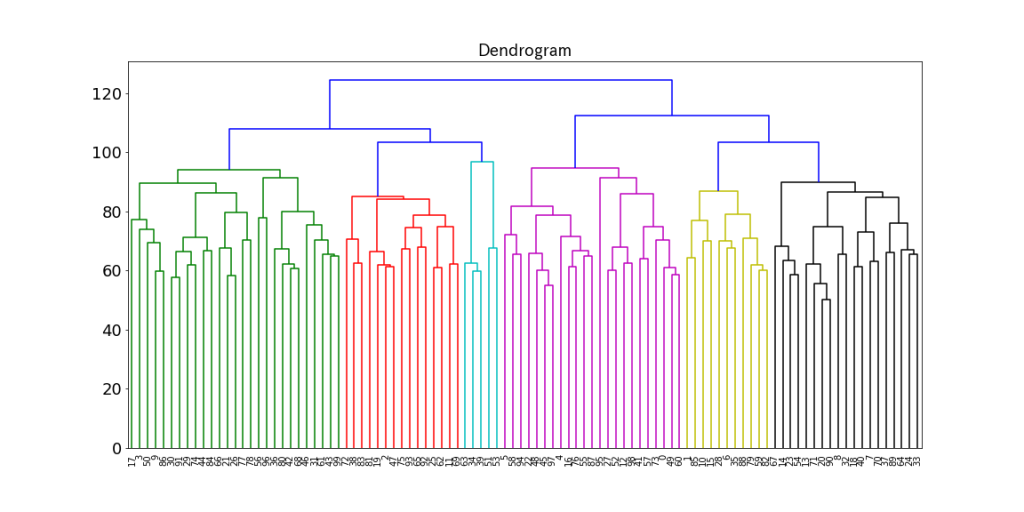
100タイトルの小説が6つに分類された。
クラスター分析結果を検証する
グラフを見る限りそれぞれの小説の類似度は高いとは言えず満遍なく分布している。念のため小説の特徴にあった分類がされているか目視で確認する。(機械的に確認する処理の作成は次回)3、5のクラスターは比較的特徴がわかりやすい。
| 63 | 3 | レベル1だけどユニークスキルで最強です |
| 51 | 3 | 乙女ゲー世界はモブに厳しい世界です |
| 53 | 3 | 俺は星間国家の悪徳領主! |
| 39 | 3 | 没落予定の貴族だけど、暇だったから魔法を極めてみた |
| 34 | 3 | 貴族転生~恵まれた生まれから最強の力を得る |
| 82 | 5 | 転生王女は今日も旗を叩き折る。 |
| 88 | 5 | 甘く優しい世界で生きるには |
| 79 | 5 | 今度は絶対に邪魔しませんっ! |
| 15 | 5 | 謙虚、堅実をモットーに生きております! |
| 10 | 5 | 一億年ボタンを連打した俺は、気付いたら最強になっていた~落第剣士の学院無双~ |
| 35 | 5 | 乙女ゲームの破滅フラグしかない悪役令嬢に転生してしまった… |
| 6 | 5 | 陰の実力者になりたくて!【web版】 |
| 1 | 5 | ありふれた職業で世界最強 |
| 59 | 5 | ループ7回目の悪役令嬢は、元敵国で自由気ままな花嫁(人質)生活を満喫する |
| 28 | 5 | 公爵令嬢の嗜み |
| 85 | 5 | 黒の魔王 |
クラスター3の特徴は「異世界 貴族 中世 SF 最強 男主人公」だろうか。クラスター5は「異世界 乙女ゲーム 女主人公 成り上がり」だろうか。
まとめ
それなりに意味のあるまとまりになっている気がするがなかなか厳しい。次回はその他のクラスターについても特徴を検証してみる。