小説を読もうの累計ランキングをDoc2Vecで解析する その4の続き。
形態素解析をする前に正規化処理を追加した。それ以外には類似文章の検索結果が良くなるように、文章数と1文章当たりの文字数、次元数などを調整した。
その代わり類似単語の検索については悪化しているように感じる。
追記(2020/09/16):
指定したURLの小説の類似小説を表示する関数を追加した。
Technical Notes
小説を読もうの累計ランキングをDoc2Vecで解析する その4の続き。
形態素解析をする前に正規化処理を追加した。それ以外には類似文章の検索結果が良くなるように、文章数と1文章当たりの文字数、次元数などを調整した。
その代わり類似単語の検索については悪化しているように感じる。
追記(2020/09/16):
指定したURLの小説の類似小説を表示する関数を追加した。
小説を読もうの累計ランキングをDoc2Vecで解析する その3の続き。
今回はこれまで解析した特徴を表にプロットして可視化してみる。2次元の表にプロットするために、t-SNEを使用し次元を削減する。
import numpy as np
import matplotlib.pyplot as plt
from gensim.models.doc2vec import Doc2Vec
from sklearn.manifold import TSNE
# 学習済みモデルを読み込む
m = Doc2Vec.load('drive/My Drive/Colab Notebooks/syosetu/doc2vec.model')
weights = []
for i in range(0, len(m.docvecs)):
weights.append(m.docvecs[i].tolist())
weights_tuple = tuple(weights)
X = np.vstack(weights_tuple)
# t-SNEで次元圧縮する
tsne_model = TSNE(n_components=2, random_state=0, verbose=2)
np.set_printoptions(suppress=True)
t_sne = tsne_model.fit_transform(X)
# クラスタリング済みのデータを読み込む
with open('drive/My Drive/Colab Notebooks/syosetu/novel_cluster.csv', 'r') as f:
reader = csv.reader(f)
clustered = np.array([row for row in reader])
clustered = clustered.astype(np.dtype(int).type)
clustered = clustered[np.argsort(clustered[:, 0])]
clustered = clustered.T[1]
# グラフ描画
fig, ax = plt.subplots(figsize=(10, 10), facecolor='w', edgecolor='k')
# Set Color map
cmap = plt.get_cmap('Dark2')
for i in range(t_sne.shape[0]):
cval = cmap(clustered[i] / 4)
ax.scatter(t_sne[i][0], t_sne[i][1], marker='.', color=cval)
ax.annotate(i, xy=(t_sne[i][0], t_sne[i][1]), color=cval)
plt.show()
実行すると以下のようなグラフになった。満遍なく分布しているが同じクラスターの小説についてはある程度まとまって分布しているように見える。
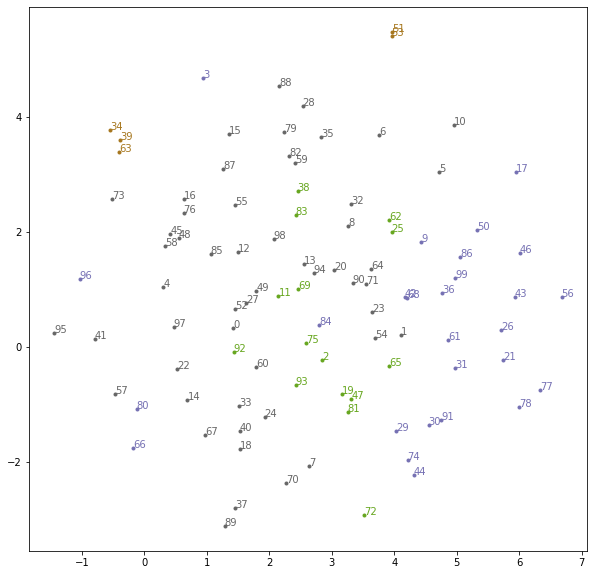
続いて3次元のグラフを描画してくれる良いページがあるので使ってみる。
Embedding projector – visualization of high-dimensional data
上記のサイトで次元圧縮を行ってくれるので、こちらはTSV形式のデータを用意するだけで良い。
!pip install gensim torch tensorboardX
from torch import FloatTensor
from gensim.models import KeyedVectors
from tensorboardX import SummaryWriter
m = KeyedVectors.load('drive/My Drive/Colab Notebooks/syosetu/doc2vec.model')
weights = []
labels = []
for i in range(0, len(m.docvecs)):
weights.append(m.docvecs[i].tolist())
labels.append(m.docvecs.index_to_doctag(i))
# DEBUG: visualize vectors up to 1000
weights = weights[:1000]
labels = labels[:1000]
writer = SummaryWriter()
writer.add_embedding(FloatTensor(weights), metadata=labels)
実行すると「/content/runs/実行日付等/00000/default」にtensors.tsvとmetadata.tsvファイルが保存される。このファイルをEmbedding Projectorのページにアップロードする。
このままではどの点がどの小説を表しているかわかりずらいので、metadata.tsvを加工してタイトルが表示されるようにする。
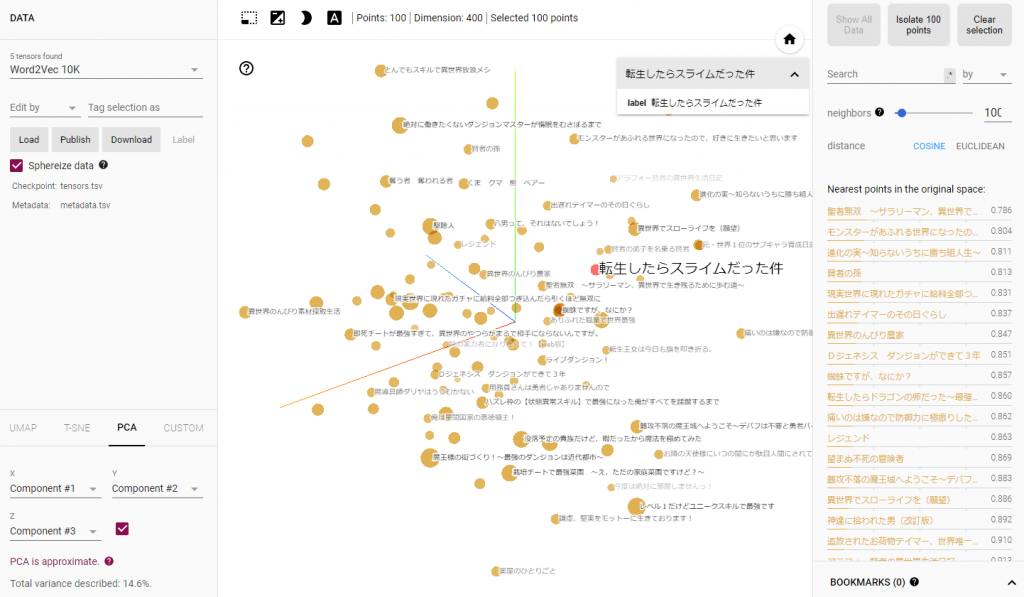
とても見やすいけれども、第1から第3主成分までの累積寄与率が14%ほどしかないので、PCAにて次元圧縮したこのグラフは残念ながら殆どあてにならない。PCA以外にも先ほど使用したt-SNEを使用することも可能。
もう少しきれいなグラフが描けるように、ライブラリの使い方から勉強しなおす。
小説を読もうの累計ランキングをDoc2Vecで解析する その2の続き。
前回累積ランキングのクラスターを目視で確認をしたが、それぞれの特徴を的確に捉えることは出来なかった。今回はクラスターの特徴をTF-IDFを使って抽出してみる。
今回もscikit-learnのライブラリを使用する。
import csv
from sklearn.feature_extraction.text import TfidfVectorizer
# 小説の本文を読み込む
with open('drive/My Drive/Colab Notebooks/syosetu/novel_datas.txt', 'r') as f:
novels = [[i, data.split('\t')[2]] for i, data in enumerate(f)]
docs = ['','','','','','']
# クラスタリング結果を読み込む
with open('drive/My Drive/Colab Notebooks/syosetu/novel_cluster.csv', 'r') as f:
reader = csv.reader(f)
for row in reader:
doc = novels[int(row[0])][1]
#doc = ' '.join(set(doc.split())) #同一タイトル内で重複削除
# クラスター毎に本文を纏める
docs[int(row[1]) - 1] += ' {0}'.format(doc)
# tf-idfの計算
vectorizer = TfidfVectorizer(max_df=0.90, max_features=100)
# 文書全体の90%以上で出現する単語は無視する
# 且つ、出現上位100までの単語で計算する
X = vectorizer.fit_transform(docs)
#print('feature_names:', vectorizer.get_feature_names())
words = vectorizer.get_feature_names()
for doc_id, vec in zip(range(len(docs)), X.toarray()):
print('doc_id:', doc_id + 1)
for w_id, tfidf in sorted(enumerate(vec), key=lambda x: x[1], reverse=True)[:20]:
lemma = words[w_id]
print('\t{0:s}: {1:f}'.format(lemma, tfidf))
実行結果は以下の通りとなった。
doc_id: 1
蔵人: 0.364076
魔物: 0.334649
ベルグリフ: 0.296258
魔王: 0.271560
アンジェリン: 0.264133
直継: 0.237363
ガリウス: 0.205239
魔術: 0.199051
lv: 0.197992
夜霧: 0.196315
マイン: 0.194641
パーティ: 0.190183
身体: 0.161838
女神: 0.156352
ハンター: 0.127054
魔族: 0.118583
メンバー: 0.107892
探索者: 0.106833
公爵: 0.104819
バス: 0.093903
doc_id: 2
魔物: 0.409209
ダリヤ: 0.387583
dp: 0.376927
ポーション: 0.287506
lv: 0.255560
lv: 0.232489
クマ: 0.227815
ゴブリン: 0.226827
聖女: 0.159725
薬草: 0.142533
魔石: 0.131330
兄さん: 0.124231
契約: 0.119544
討伐: 0.111881
加護: 0.104218
hp: 0.102685
ボックス: 0.094060
金貨: 0.082761
騎士団: 0.082761
パン: 0.079863
doc_id: 3
リアム: 0.810088
ドロップ: 0.416766
導書: 0.335092
領地: 0.152304
hp: 0.102806
殿下: 0.101409
スケルトン: 0.076152
mp: 0.049499
皇帝: 0.044091
キャラ: 0.041884
王子: 0.030461
兄さん: 0.017636
冒険: 0.011423
母さん: 0.011423
クマ: 0.010291
報酬: 0.007615
経験値: 0.007615
付与: 0.003808
契約: 0.003808
採取: 0.003808
doc_id: 4
名無し: 0.424656
スバル: 0.420209
コタロー: 0.326830
真昼: 0.262535
鑑定: 0.215285
耐性: 0.200477
ニート: 0.193944
ボーナス: 0.187787
魔物: 0.174278
ポーション: 0.166195
lv: 0.163557
ガチャ: 0.158615
ゴブリン: 0.158331
lv: 0.155643
プレイヤー: 0.132132
盗賊: 0.129854
身体: 0.105934
ユニーク: 0.091012
初期: 0.088848
キャラ: 0.084291
doc_id: 5
リーシェ: 0.737429
王子: 0.384356
アルノルト: 0.342548
殿下: 0.235180
学院: 0.227594
公爵: 0.123912
皇帝: 0.118855
バス: 0.103287
先生: 0.096089
剣士: 0.085170
訓練: 0.076434
母さん: 0.056780
学校: 0.054596
聖女: 0.053105
身体: 0.048044
それなり: 0.043677
キャラ: 0.034941
所属: 0.034941
騎士団: 0.030574
メンバー: 0.028390
doc_id: 6
魔物: 0.419558
lv: 0.318543
素材: 0.269150
幼女: 0.265192
魔術: 0.261251
レイ: 0.259408
身体: 0.239465
マイン: 0.205894
ゴブリン: 0.205821
魔石: 0.199376
爺さん: 0.186030
転移: 0.178751
万能: 0.166240
それなり: 0.112806
銀貨: 0.112292
採取: 0.104890
おじさん: 0.103126
金貨: 0.096973
美女: 0.094994
訓練: 0.094994
形態素解析をしたときに残ってしまった人名がいくつか含まれてしまっているが今回は無視する。
また、予想はしていたがサンプル数が少ないことと、似ている内容が多いため特徴がわかり難くなってしまった。それでもある程度の特徴はつかむことが出来た。
doc_id: 1
戦闘、戦争中心の話?
doc_id: 2
ダンジョン中心の話?
doc_id: 3
領地経営、内政中心の話?
doc_id: 4
ファンタジーだけど現実要素強めの話?
doc_id: 5
乙女ゲーム、内政中心の話?
doc_id: 6
戦闘、戦争は少なそう。まったり系、生産系の話?
教師無しであるにもかかわらず、ちゃんと分類出来るのは面白い。最終的にやりたいことは自分が読みたいと思う小説を機械学習で探すことなので、今回の知見を後に生かせれば良いと思う。
小説を読もうの累計ランキングをDoc2Vecで解析するの続き。
前回学習済みモデルによって小説間の類似度を見ることが出来た。今度はクラスタリングを行う。
次に進む前に少しスクレイピングの処理を修正する。1から5話まで取得する様にしていたが、作品によって1話当たりの文字数にかなり差があるので、単語数を基準に本文を取得するように変更する。またサンプルをTop 100(これでもかなり少ない)まで増やす。
# 累計ランキングをTop100まで取得
def novel_total():
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
r = requests.get('http://yomou.syosetu.com/rank/list/type/total_total/', headers=headers, timeout=20)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text)
rank_index = soup.find_all('div', class_='rank_h')
sleep(1)
with open('drive/My Drive/Colab Notebooks/syosetu/novel_datas.txt', 'w') as f:
for rank in range(100):
link = rank_index[rank].find('a')
url = link.get('href')
title = link.get_text()
# 後でわかりやすいようにURLと小説のタイトルを設定
f.write('{0}\t{1}\t'.format(url, title))
print('rank:{0} title:{1}'.format(rank + 1, title))
chapter = 0
word_count = 0
while word_count < 5000 and chapter < 40:
# 単語が5000未満かつ、40話以下の間繰り返し取得する
try:
words = keitaiso(novel_text_dler('{0}{1}/'.format(url, chapter + 1)))
except (HTTPError, URLError) as e:
print(e)
break
except socket.timeout as e:
print(e)
continue
else:
f.write(words)
print('chapter:{0}'.format(chapter + 1))
word_count += len(words.split())
chapter += 1
f.write('\n')
モデルを作成するパラメーターも少し変更する。
# 学習の実行
m = Doc2Vec(documents=trainings, dm=1, vector_size=400, min_count=4, workers=4, epochs=40)
実行結果を確認する。
m = Doc2Vec.load('drive/My Drive/Colab Notebooks/syosetu/doc2vec.model')
# 0番目の小説に似ている小説は?(0番目の小説のタイトルは、「転生したらスライムだった件」)
print(m.docvecs.most_similar(0))
前回:
[(27, 0.3229605555534363), (11, 0.27810564637184143), (42, 0.24812708795070648), (13, 0.2365787774324417), (29, 0.22865955531597137), (33, 0.21636559069156647), (22, 0.19751328229904175), (20, 0.18333640694618225), (36, 0.1763637661933899), (25, 0.1638755202293396)]
今回:
[(27, 0.2789984941482544), (13, 0.26930510997772217), (60, 0.2584960460662842), (48, 0.25848516821861267), (68, 0.24882027506828308), (33, 0.24246476590633392), (49, 0.23103246092796326), (52, 0.22929105162620544), (94, 0.22420653700828552), (12, 0.22121790051460266)]
一番目が「27:モンスターがあふれる世界になったので、好きに生きたいと思います」であるのは変更なしであるが、二番目には「13:異世界のんびり農家」が出て来た。チートぐらいしか共通点はなさそう。試しにwindowをデフォルトの8から16に増やしてみる。
するとこのようになった。
[(60, 0.3200589418411255), (52, 0.3115108609199524), (27, 0.31150585412979126), (49, 0.2996276319026947), (13, 0.299365371465683), (18, 0.2926834225654602), (97, 0.2818679213523865), (12, 0.2745039761066437), (29, 0.2639138996601105), (68, 0.2628819942474365)]
一番目は「60:聖者無双 ~サラリーマン、異世界で生き残るために歩む道~」、二番目は「52:進化の実~知らないうちに勝ち組人生~」となった。今度は「残酷な描写あり」、「異世界」、「ハーレム」、「チート」と共通点は多そうなのでこちらを採用する。
今回も「Doc2Vecを使って小説家になろうで自分好みの小説を見つけたい話」を参考にさせて頂いた。
これらは便利な関数が用意されているので、それらに値を渡すだけでクラスタリングから図の作成まで行える。
import numpy as np
import matplotlib.pyplot as plt
from gensim.models.doc2vec import Doc2Vec
from scipy.cluster.hierarchy import linkage, fcluster, dendrogram
from matplotlib.font_manager import FontProperties
# 階層型クラスタリングの実施
def hierarchical_clustering(emb, threshold):
# ウォード法 x ユークリッド距離
linkage_result = linkage(emb, method='ward', metric='euclidean')
# クラスタ分けするしきい値を決める
threshold_distance = threshold * np.max(linkage_result[:, 2])
# クラスタリング結果の値を取得
clustered = fcluster(linkage_result, threshold_distance, criterion='distance')
print("end clustering.")
return linkage_result, threshold_distance, clustered
# 階層型クラスタリングの可視化
def plot_dendrogram(linkage_result, doc_labels, threshold):
fp = FontProperties(fname=r'drive/My Drive/Colab Notebooks/IPAexfont00301/ipaexg.ttf')
plt.figure(figsize=(16, 8), facecolor='w', edgecolor='k')
dendrogram(linkage_result, labels=doc_labels, color_threshold=threshold)
plt.title('Dendrogram', fontproperties=fp)
plt.xticks(fontsize=10)
print('end plot.')
plt.savefig('drive/My Drive/Colab Notebooks/syosetu/novel_hierarchy.png')
# 階層型クラスタリング結果の保存
def save_cluster(doc_index, clustered):
doc_cluster = np.array([doc_index, clustered])
doc_cluster = doc_cluster.T
doc_cluster = doc_cluster.astype(np.dtype(int).type)
doc_cluster = doc_cluster[np.argsort(doc_cluster[:, 1])]
np.savetxt('drive/My Drive/Colab Notebooks/syosetu/novel_cluster.csv', doc_cluster, delimiter=',', fmt='%.0f')
print('save cluster.')
m = Doc2Vec.load('drive/My Drive/Colab Notebooks/syosetu/doc2vec.model')
vectors_list = [m.docvecs[n] for n in range(len(m.docvecs))]
threshold = 0.8
linkage_result, threshold, clustered = hierarchical_clustering(emb=vectors_list, threshold=threshold)
plot_dendrogram(linkage_result=linkage_result, doc_labels=list(range(100)), threshold=threshold)
save_cluster(list(range(100)), clustered)
実行すると以下のような画像が表示される。
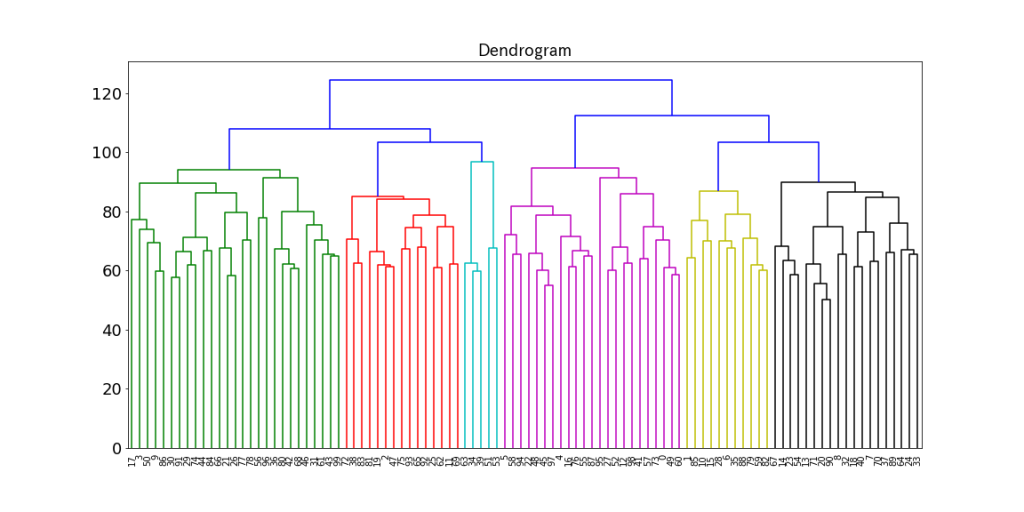
100タイトルの小説が6つに分類された。
グラフを見る限りそれぞれの小説の類似度は高いとは言えず満遍なく分布している。念のため小説の特徴にあった分類がされているか目視で確認する。(機械的に確認する処理の作成は次回)3、5のクラスターは比較的特徴がわかりやすい。
| 63 | 3 | レベル1だけどユニークスキルで最強です |
| 51 | 3 | 乙女ゲー世界はモブに厳しい世界です |
| 53 | 3 | 俺は星間国家の悪徳領主! |
| 39 | 3 | 没落予定の貴族だけど、暇だったから魔法を極めてみた |
| 34 | 3 | 貴族転生~恵まれた生まれから最強の力を得る |
| 82 | 5 | 転生王女は今日も旗を叩き折る。 |
| 88 | 5 | 甘く優しい世界で生きるには |
| 79 | 5 | 今度は絶対に邪魔しませんっ! |
| 15 | 5 | 謙虚、堅実をモットーに生きております! |
| 10 | 5 | 一億年ボタンを連打した俺は、気付いたら最強になっていた~落第剣士の学院無双~ |
| 35 | 5 | 乙女ゲームの破滅フラグしかない悪役令嬢に転生してしまった… |
| 6 | 5 | 陰の実力者になりたくて!【web版】 |
| 1 | 5 | ありふれた職業で世界最強 |
| 59 | 5 | ループ7回目の悪役令嬢は、元敵国で自由気ままな花嫁(人質)生活を満喫する |
| 28 | 5 | 公爵令嬢の嗜み |
| 85 | 5 | 黒の魔王 |
クラスター3の特徴は「異世界 貴族 中世 SF 最強 男主人公」だろうか。クラスター5は「異世界 乙女ゲーム 女主人公 成り上がり」だろうか。
それなりに意味のあるまとまりになっている気がするがなかなか厳しい。次回はその他のクラスターについても特徴を検証してみる。
小説を読もうの累計ランキングをDoc2Vecで解析して、色々遊んでみる。
「Doc2Vecを使って小説家になろうで自分好みの小説を見つけたい話」を参考にさせて頂いた。
(9/2 追記: 下記のコードを修正してGitHub Gistに載せました。=> 小説を読もうの累計ランキングをDoc2Vecで解析する その5)
Google Colaboratoryを使ってプログラムを作成していくため、まずは諸々必要なものをインストールする。
!apt install aptitude swig
!aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
!pip install mecab-python3 unidic-lite
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
!echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n -a
前準備として、形態素解析を行い文章を単語毎に分ける必要がある。その時日本語辞書が必要になるが、今回はmecab-ipadic-NEologdを使うことにした。小説を読もうの文章には新しい表現が多いと思われるため、多数のWeb上の言語資源から得た新語を追加することでカスタマイズされているこの辞書が最適と判断した。
以下のコードで実際にスクレイピングし、文章を取得し形態素解析を行ってからGoogle Driveに保存する。(Google Driveをマウントする方法はこちらを参照)
import requests
import subprocess
import MeCab
from bs4 import BeautifulSoup
from time import sleep
# 本文をダウンロード
def novel_text_dler(url):
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text)
honbun = soup.find_all('div', class_='novel_view')
novel = ''
for text in honbun:
novel += text.text
sleep(1)
return novel
# 形態素解析
def keitaiso(text):
cmd = 'echo `mecab-config --dicdir`"/mecab-ipadic-neologd"'
path = (subprocess.Popen(cmd, stdout=subprocess.PIPE, shell=True).communicate()[0]).decode('utf-8')
tagger = MeCab.Tagger('-d {0}'.format(path))
tagger.parse('')
node = tagger.parseToNode(text)
word = ''
pre_feature = ''
while node:
# 名詞、形容詞、動詞、形容動詞であるか判定
HANTEI = "名詞" in node.feature
HANTEI = "形容詞" in node.feature or HANTEI
HANTEI = "動詞" in node.feature or HANTEI
HANTEI = "形容動詞" in node.feature or HANTEI
# 以下に該当する場合は除外(ストップワード)
HANTEI = (not "代名詞" in node.feature) and HANTEI
HANTEI = (not "助動詞" in node.feature) and HANTEI
HANTEI = (not "非自立" in node.feature) and HANTEI
HANTEI = (not "数" in node.feature) and HANTEI
HANTEI = (not "人名" in node.feature) and HANTEI
if HANTEI:
if ("名詞接続" in pre_feature and "名詞" in node.feature) or ("接尾" in node.feature):
word += '{0}'.format(node.surface)
else:
word += ' {0}'.format(node.surface)
#print('{0} {1}'.format(node.surface, node.feature))
pre_feature = node.feature
node = node.next
return word[1:]
# 累計ランキングTop50の1から5話を取得
def novel_total_50():
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
r = requests.get('http://yomou.syosetu.com/rank/list/type/total_total/', headers=headers)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text)
rank_index = soup.find_all('div', class_='rank_h')
sleep(1)
with open('drive/My Drive/Colab Notebooks/syosetu/novel_datas.txt', 'w') as f:
for rank in range(50):
link = rank_index[rank].find('a')
url = link.get('href')
# 後でわかりやすいようにURLと小説のタイトルを設定
f.write(url + '\t' + link.get_text() + '\t')
for chapter in range(5):
f.write(keitaiso(novel_text_dler(url + str(chapter + 1) + '/')))
f.write('\n')
novel_total_50()
準備が出来たら、Doc2Vecを実行し学習済みモデルを作成する。
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
# 空白で単語を区切り、改行で文書を区切っているテキストデータ
with open('drive/My Drive/Colab Notebooks/syosetu/novel_datas.txt', 'r') as f:
# 文書ごとに単語を分割してリストにする
trainings = [TaggedDocument(words = data.split('\t')[2].split(), tags=[i]) for i, data in enumerate(f)]
# 学習の実行
m = Doc2Vec(documents=trainings, dm=1, vector_size=200, window=8, min_alpha=1e-4, min_count=5, sample=1e-3, workers=4, epochs=40)
# モデルを保存
m.save('drive/My Drive/Colab Notebooks/syosetu/doc2vec.model')
学習済みモデルが作成出来たのでこれを使って色々遊んでみる。
m = Doc2Vec.load('drive/My Drive/Colab Notebooks/syosetu/doc2vec.model')
# 0番目の小説に似ている小説は?(0番目の小説のタイトルは、「転生したらスライムだった件」)
print(m.docvecs.most_similar(0))
すると以下のような結果が表示された。
[(27, 0.3229605555534363), (11, 0.27810564637184143), (42, 0.24812708795070648), (13, 0.2365787774324417), (29, 0.22865955531597137), (33, 0.21636559069156647), (22, 0.19751328229904175), (20, 0.18333640694618225), (36, 0.1763637661933899), (25, 0.1638755202293396)]
最初の3つの小説のタイトルは、以下の通り。
27:モンスターがあふれる世界になったので、好きに生きたいと思います
11:蜘蛛ですが、なにか?
42:即死チートが最強すぎて、異世界のやつらがまるで相手にならないんですが。
そもそも、類似度が高くても0.32なので似ている小説はないと見た方がよさそう。
もう少し特徴のある小説を選んで検索してみる。
# 28番目の小説に似ている小説は?(28番目の小説のタイトルは、「公爵令嬢の嗜み」)
print(m.docvecs.most_similar(28))
すると今度は以下のような結果が表示された。
[(35, 0.5070601105690002), (46, 0.35368871688842773), (47, 0.34039080142974854), (15, 0.32830286026000977), (7, 0.30432310700416565), (5, 0.2750416100025177), (8, 0.24726390838623047), (38, 0.23762762546539307), (12, 0.21315187215805054), (17, 0.20340490341186523)]
最初の3つの小説のタイトルは、以下の通り。
35:乙女ゲームの破滅フラグしかない悪役令嬢に転生してしまった…
46:(´・ω・`)最強勇者はお払い箱→魔王になったらずっと俺の無双ターン
47:転生した大聖女は、聖女であることをひた隠す
今度は類似度0.5の小説が出てきたが、タイトルを見る限りかなり似ている気がする。それぞれの小説のタグも「R15 異世界転生 悪役令嬢 転生」、「異世界転生 乙女ゲーム 悪役令嬢 転生 悪役 魔法 逆ハー(性別問わず) 犬とは犬猿の仲」となっているため、小説の内容も近いものと思われる。
# 魔法に似た単語は?
print(m.wv.most_similar('魔法'))
以下のような実行結果になった。
[(‘使える’, 0.5868769884109497), (‘基礎式’, 0.5487741827964783), (‘古代’, 0.5475476384162903), (‘全属性’, 0.5122957229614258), (‘氷’, 0.5110565423965454), (‘基礎’, 0.5063040256500244), (‘失われ’, 0.5040603280067444), (‘火炎’, 0.4972696006298065), (‘初級’, 0.4933454394340515), (‘トーチ’, 0.48877549171447754)]
類似度が大体0.5程度の単語が出て来ているが、出てきた理由が良くわからない単語も含まれている。これは魔法という単語が小説を読もう内で広範囲に使われているせいだろうか。
# スライムに似た単語は?
print(m.wv.most_similar('スライム'))
今度は以下のような実行結果になった。
[(‘マザースライム’, 0.7109331488609314), (‘消化’, 0.7005775570869446), (‘栄養’, 0.7005000114440918), (‘キャタピラー’, 0.6742416620254517), (‘魔獣’, 0.6534003019332886), (‘グリーン’, 0.6487153768539429), (‘スティッキースライム’, 0.6390945911407471), (‘野生’, 0.6230173707008362), (‘食べさせ’, 0.609244167804718), (‘分裂’, 0.5920956134796143)]
こちらはかなり良好な実行結果になっていると思われる。
さらにDoc2Vecは文字の足し算引き算をすることが出来る。
# 魔法に水を足す
print(m.wv.most_similar(positive=['魔法', '水']))
# 魔法から最強を引く
print(m.wv.most_similar(positive=['魔法'], negative=['最強']))
それぞれ、実行結果は以下の通り。
[(‘氷’, 0.6695120334625244), (‘出せる’, 0.6237022280693054), (‘火’, 0.6203511953353882), (‘風’, 0.5940117239952087), (‘水魔法’, 0.5882148146629333), (‘雷’, 0.5841056108474731), (‘風魔法’, 0.5786388516426086), (‘属性’, 0.5733253955841064), (‘SS’, 0.5640972852706909), (‘唱え’, 0.563363254070282)]
[(‘氷’, 0.5235071182250977), (‘電気’, 0.4570558965206146), (‘トーチ’, 0.4391556680202484), (‘指先’, 0.4334547519683838), (‘唱え’, 0.4241408109664917), (‘おー’, 0.40032967925071716), (‘イメージ’, 0.388439416885376), (‘驚く’, 0.3821325898170471), (‘ゴブリン・ソーサラー’, 0.3783293664455414), (‘魔炎’, 0.3754980266094208)]
魔法に水を足した場合と、最強を引いた場合の最も類似度の高い単語が同じ「氷」になり面白い結果になった。
学習していない小説も、学習済みモデルを使用してベクトル化することが出来る。これを使うと学習済み小説の中から似ている小説を探すことが出来る。
# 本来は小説の本文を形態素解析するべきだが、あえて少ない文字で検索してみる
x = m.infer_vector(keitaiso('主人公最弱 ヒロイン最強'))
print(m.docvecs.most_similar([x]))
実行結果は以下の通り。
[(29, 0.3471960127353668), (26, 0.3468911945819855), (42, 0.34553420543670654), (48, 0.33736804127693176), (6, 0.3323182463645935), (32, 0.3290942907333374), (27, 0.3264150023460388), (38, 0.3221890926361084), (19, 0.30004316568374634), (17, 0.29801973700523376)]
最初の3つの小説のタイトルは、以下の通り。
29:望まぬ不死の冒険者
26:魔王様の街づくり!~最強のダンジョンは近代都市~
42:即死チートが最強すぎて、異世界のやつらがまるで相手にならないんですが。
「望まぬ不死の冒険者」は最初のうちは主人公が弱かったはず。5話までしかスクレイピングしていないため、このような結果になったと思われる。「魔王様の街づくり!」も成り上がり系だから同様と思われる。「即死チート」はよくわからず。さすがにサンプル不足のため、検索機能として使うには厳しい実行結果となった。もう少しサンプルを増やせば変わってくるのではないだろうか。
今回はかなり少ない小説の数で実行したにも関わらず、それなりに面白い結果を得ることが出来た。もっとサンプル数を増やせば実行結果も安定してくるのではないだろうか。