Stable Diffusion web UIをWindows 11のローカル環境で実行するための、覚書。
目次
環境
- Windows 11
- GeForce 10以上のGPUがインストールされている
事前準備
- Pythonをインストールする
- Gitをインストールする
Stable Diffusion web UI
Pythonをインストールする
Windows 11を使用しているなら、Microsoft Storeからインストールする。Pythonで検索して、バージョンは3.10を選択する。
コマンドプロンプトで下記のコマンドを実行して、Pythonの後にバージョンが表示されればインストール成功。
> python --version
Python 3.10.10
Gitをインストールする
Git for Windowsのサイトからインストーラーをダウンロードして実行する。
コマンドプロンプトで下記のコマンドを実行して、gitの後にバージョンが表示されればインストール成功。
> git --version
git version 2.39.2.windows.1
Stable Diffusion web UIのダウンロード
インストールしたいフォルダで下記のコマンドを実行する。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
> git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
Cloning into 'stable-diffusion-webui'...
remote: Enumerating objects: 17046, done.
remote: Counting objects: 100% (253/253), done.
remote: Compressing objects: 100% (173/173), done.
remote: Total 17046 (delta 148), reused 151 (delta 79), pack-reused 16793
Receiving objects: 100% (17046/17046), 27.92 MiB | 7.52 MiB/s, done.
Resolving deltas: 100% (11888/11888), done.
modelのダウンロード
Stable Diffusion web UIだけでは画像を出力することは出来ない。様々な画像を学習させて作成した「model」が必要になる。「model」の種類によってアニメ系が得意、リアル系が得意、背景が得意など色々あるが、今回は下記のアニメ系が得意なモデルをダウンロードする。画像を出力して気に入らなければ、別のモデルを探せば良い。
https://huggingface.co/andite/anything-v4.0/tree/mainのページにあるanything-v4.0-pruned.safetensors(v4.5の方が良いかも)をダウンロードして、Stable Diffusion web UIのインストールフォルダ下のmodels/Stable-diffusionフォルダに保存する。
VAEのダウンロード
VAE(変分自己符号化器)の導入は必須ではない。
必須ではないが、VAEを導入することで画像が鮮明になったり、より細かいディテールで出力されるようになる。
https://huggingface.co/stabilityai/sd-vae-ft-mse-original/tree/mainのページにあるvae-ft-mse-840000-ema-pruned.safetensorsをダウンロードして、Stable Diffusion web UIのインストールフォルダ下のmodels/VAEフォルダに保存する。
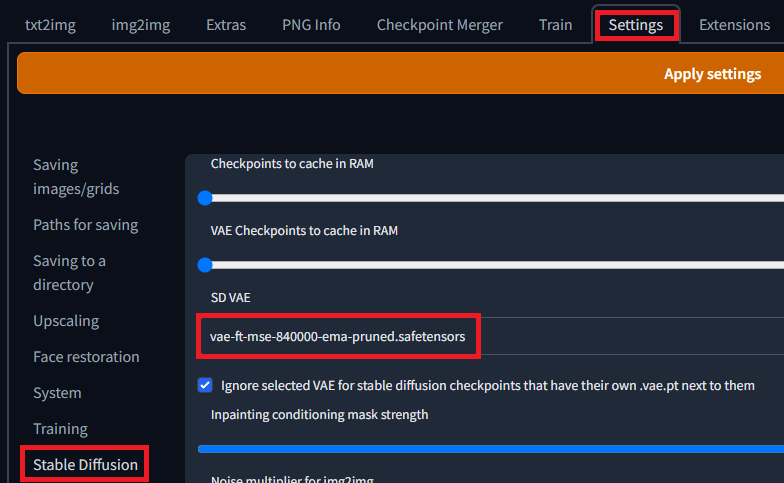
この先の手順を実行して、Stable Diffusion web UIをインストールした後に、Stable Diffusion web UIの画面上で下記の設定を行う。
画面上のメニューの「Settings」、次に左のメニューの「Stable Diffusion」をクリックし、SD VAEの項目のプルダウンからvae-ft-mse-840000-ema-pruned.safetensorsを選択し、「Apply settiongs」をクリックする。
EasyNegativeのダウンロード
Stable Diffusion web UIでは、Promptに入力したテキストによって画像の出力内容を制御する。しかし、それだけでは低品質の画像が出力されたり、足が3本あったり、指の方向がおかしい画像が出力されたりする。
そこで画像を出力するときは、Negative Promptに「(worst quality, low quality:1.4), multiple limbs」のようなお決まりの文言を入力してそれらの画像が出力されることを抑制する。EasyNegativeを使用するとそれらの面倒な入力をある程度省略することが出来るようになる。
https://huggingface.co/datasets/gsdf/EasyNegative/tree/mainのページにあるEasyNegative.safetensorsをダウンロードして、Stable Diffusion web UIのインストールフォルダ下のembeddingsフォルダに保存する。
ダウンロード後、Stable Diffusion web UIが起動中であれば再起動する。Negative PromptにEasyNegativeと入力すれば適用出来る。
Stable Diffusion web UIのインストールと実行
インストール前にダウンロードしたフォルダのwebui-user.batをエディターで開き、COMMANDLINE_ARGS=の後に–xformersを追記する。
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--xformers
call webui.bat
webui-user.batを実行する。初回起動時、実行に必要なソフトウェアが自動的にダウンロードされる。データ通信量(数GBほど)も多くかなり時間がかかる。
色々メッセージが表示されるが、下記の一文が表示さればインストールと起動が成功している。
Running on local URL: http://127.0.0.1:7860
上記のURLにブラウザからアクセスすると、下記の画面が表示される。
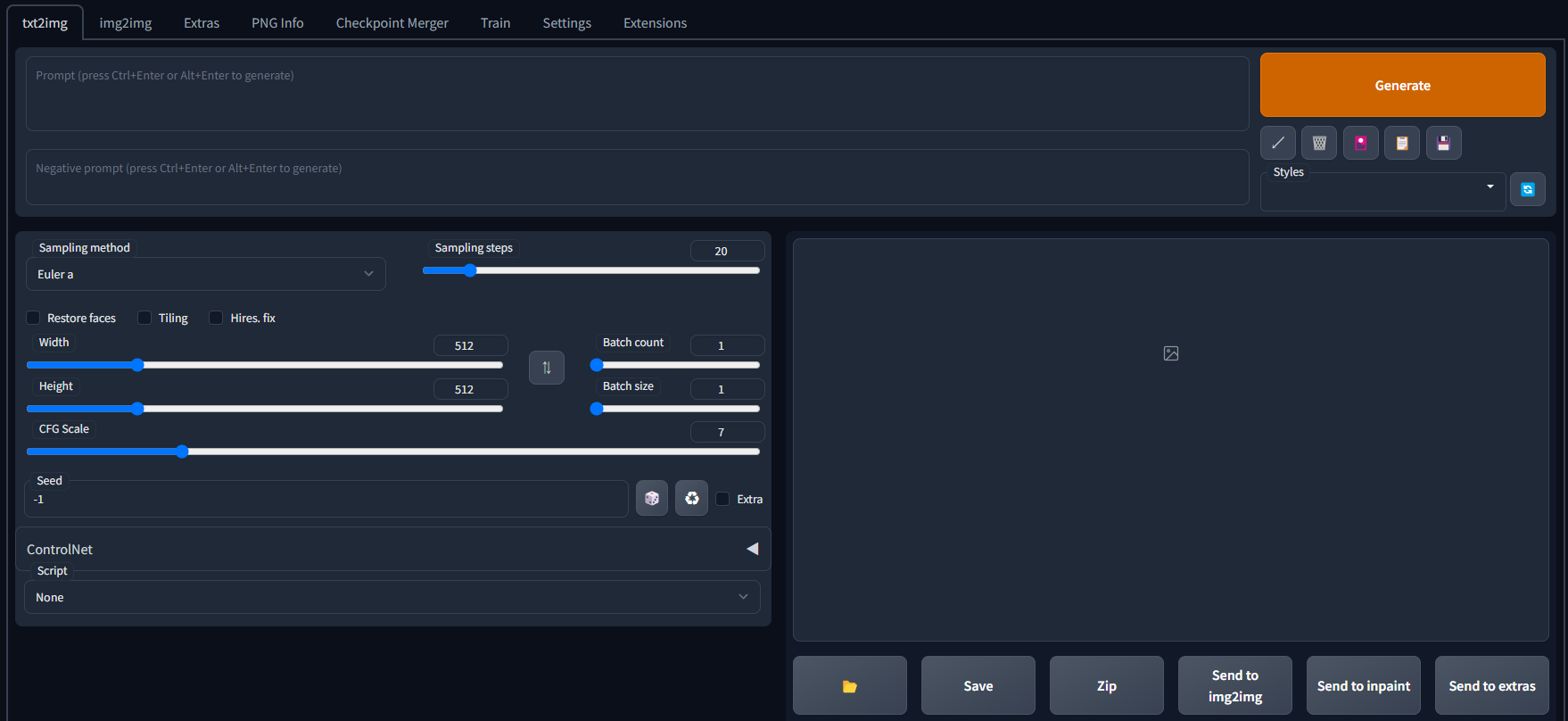
画像の出力
txt2imgタブのPromptに文言を入力し、Generateをクリックすると、画像が出力できる。しかし、最初は何を入力したら良いかわからないと思う。
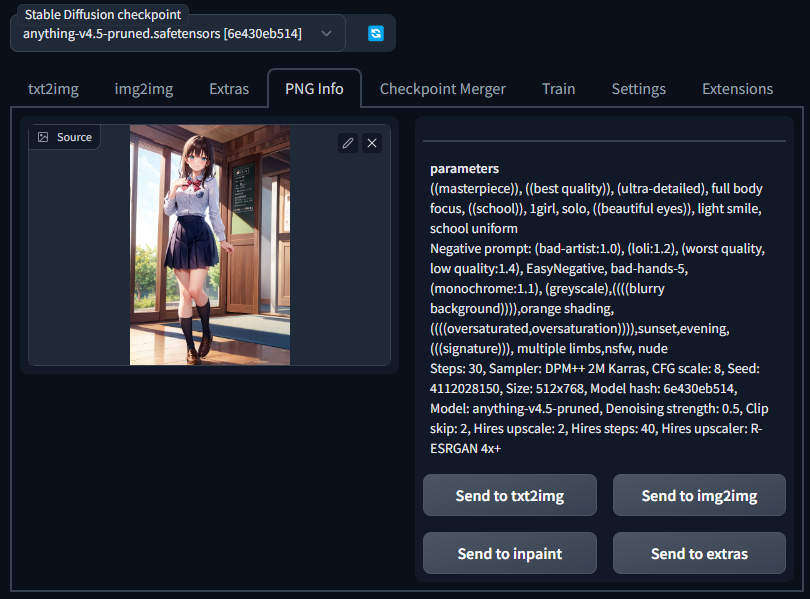
そこで、PNG Infoタブの機能を使用する。このSource欄にStable Diffusion web UIによって出力された画像をドラッグアンドドロップすると、その画像を出力したときのPromptを見ることが出来る。Promptが表示されたらSend to txt2imgをクリックすることで内容をコピーすることが出来る。
例えば、AIによって出力されたと表記されている画像を画像投稿サイトからダウンロードして、上記の機能を利用すれば同じような画像を出力出来る。
ただし、使用している「model」が違えば生成される画像はかなり違ってくるため、出来るだけ同じ「model」で出力された画像を選ぶか、同じ「model」をインストールしておく。どの「model」を使用しているかも、PNG Infoで確認出来る。
試しに下記画像をダウンロードして、画像を生成してみる。

上記の画像をダウンロードしたら、PNG InfoのSource欄にドラッグアンドドロップする。すると下記のように出力時の情報が表示されるので、Send to txt2imgをクリックする。
txt2imgに先ほどの内容が入力されたのを確認したら、Generateをクリックする。(初回実行時は時間がかかる)
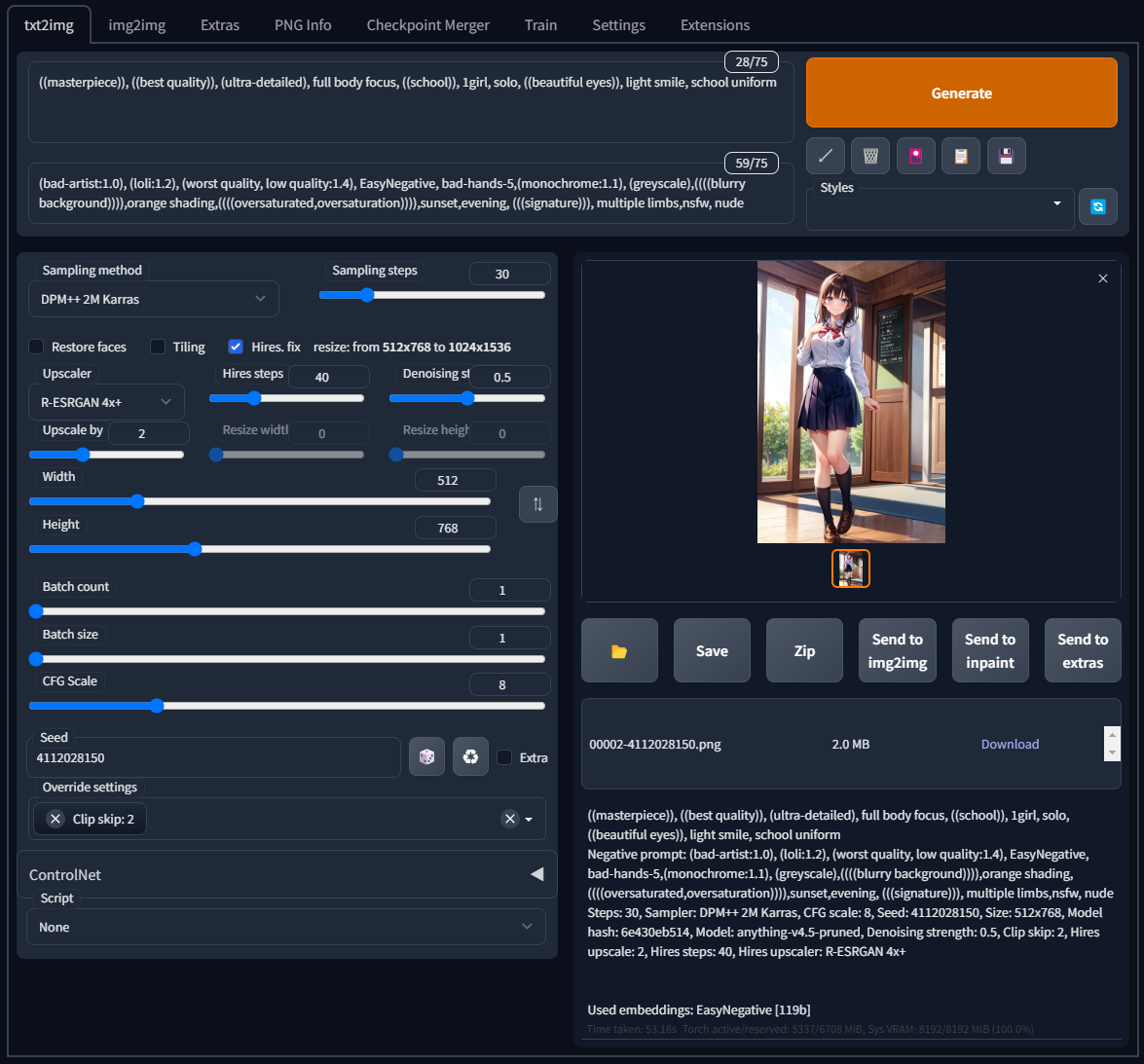
ほぼ同じ画像が出力された。Seed欄横のサイコロのようなボタンをクリックすれば、Seed値が初期化されランダム生成に変わるので、Promptの条件に沿った違う画像を出力することが出来る。
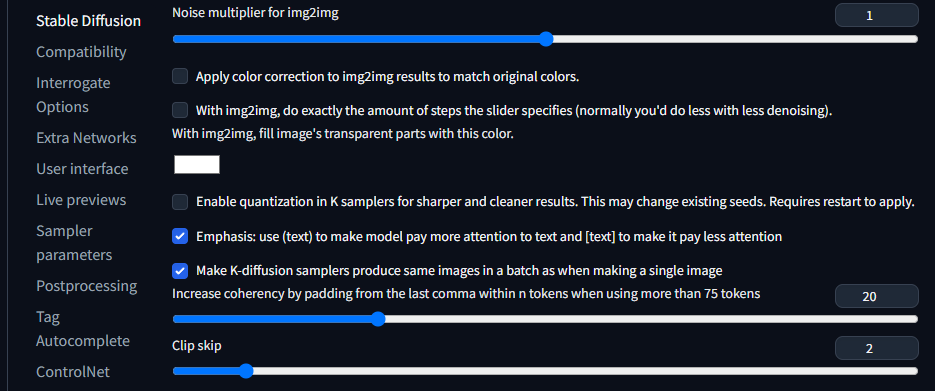
その他設定変更
Clip skipには2を設定すると良いらしい。