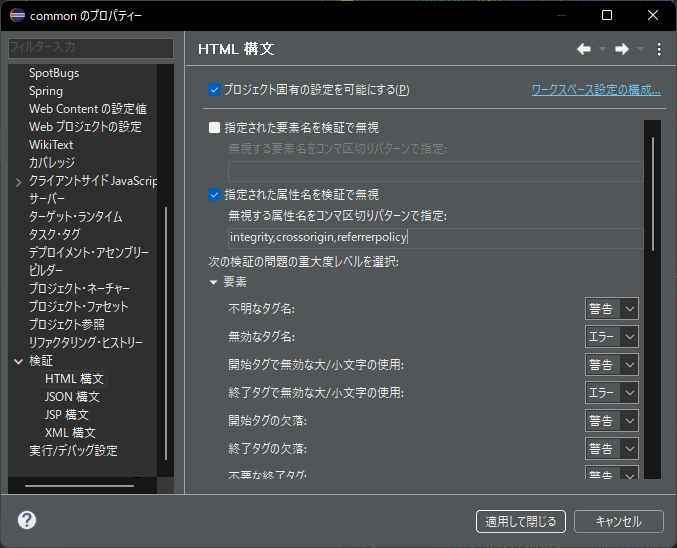
Javaにおいて変数のコピー先が変わらない例
String a = "りんご"; // (1)
String b = a; // 変数bにaを代入 (2)
System.out.println(a);
System.out.println(b);
実行結果
りんご
りんご
// 変数aに値を設定し直す
a = "みかん"; // (3)
System.out.println(a);
System.out.println(b);
実行結果
みかん
りんご
変数aは「みかん」に置き換わるが、変数bは変わらない。これは下記のようなイメージ。
(1) String a = “りんご”のイメージ
「りんご」の写真を撮り、その写真をaという箱に入れる。
(2) String a = bのイメージ
aの箱に入っている「りんご」の写真のコピーを取り、そのコピーをbの箱に入れる。
(3) a = “みかん”のイメージ
aの箱に入っていた「りんご」の写真を捨てて、aの箱に「みかん」の写真を入れる。
コピーを取ってbの箱に入れた「りんご」の写真はそのままなので、System.out.println(b)は「りんご」となる。
コピー先が変わる例
// 配列を作成する
String[] c = new String[] { "りんご", "バナナ" }; // (1)
String[] d = c; // (2)
System.out.println(d[0]);
System.out.println(d[1]);
c[0] = "みかん"; // (3)
System.out.println(d[0]);
System.out.println(d[1]);
実行結果
りんご
バナナ
みかん
バナナ
配列の要素c[0]を変更すると、d[0]の内容も変わる。これは下記のようなイメージ。
(1) String[] c = new String[] { “りんご”, “バナナ” }のイメージ
「りんご」の写真を撮って、cという棚の[0]という箱に入れる。
「バナナ」の写真を撮って、cという棚の[1]という箱に入れる。
(2) String[] d = cのイメージ
cの棚の箱を全て取り出して、中身をコピーするのは大変なので(今回は2個だけだが、通常はもっと多いことを想定している)、
dという棚の[0]の位置にcという棚の[0]を見るようにとメモを置く。
dという棚の[1]の位置にcという棚の[1]を見るようにとメモを置く。
(3) c[0] = “みかん”のイメージ
「みかん」の写真を撮って、cという棚の[0]という箱に入れる。
変数dには値のコピーはなく、参照先の情報しかないため、System.out.println(d[0])とするとc[0]の情報を参照することになり、コピー元と同様に表示される値が変わることになる。
同様に変数cとdを逆にしても、表示される値が変わる。
String[] c = new String[] { "りんご", "バナナ" };
String[] d = c;
System.out.println(c[0]);
System.out.println(c[1]);
d[0] = "みかん"; // コピー先を書き換える (4)
System.out.println(c[0]);
System.out.println(c[1]);
実行結果
りんご
バナナ
みかん
バナナ
(4) d[0] = “みかん”のイメージ
「みかん」の写真を撮って、dという棚の[0]という箱に入れようとしたら、そこに箱はなく、cという棚の[0]を見るようにとメモがあったので、cという棚の[0]の箱の中に「みかん」の写真を入れる。
(4)の操作でc[0]の内容が変わってしまっているので、System.out.println(c[0])の出力も「みかん」になる。