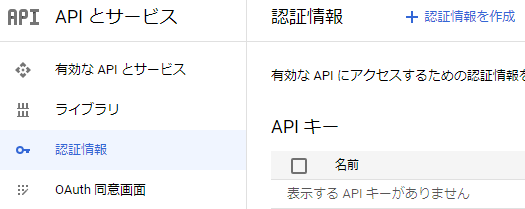
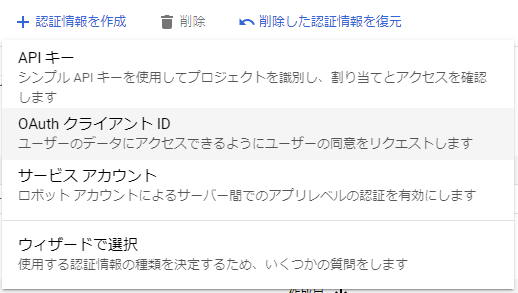
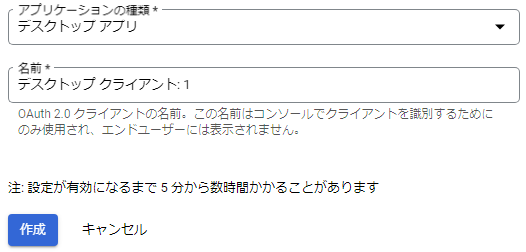
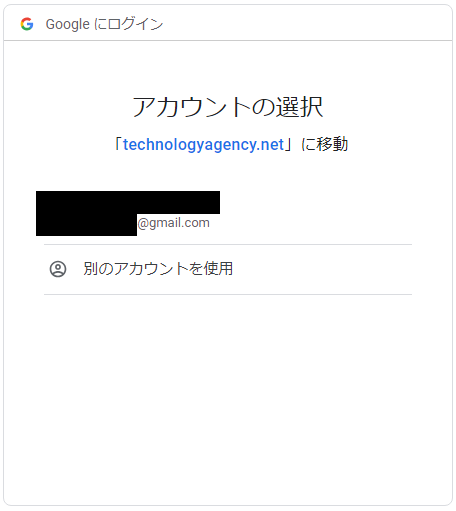
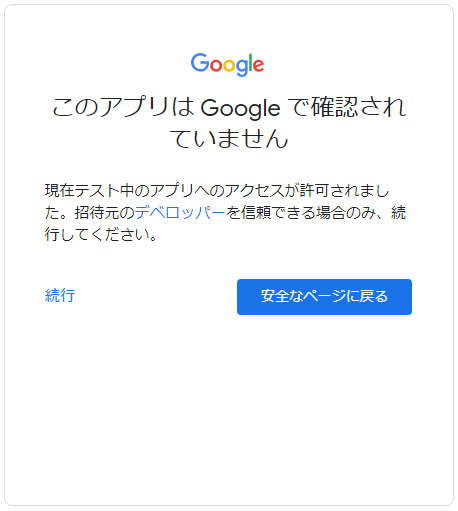
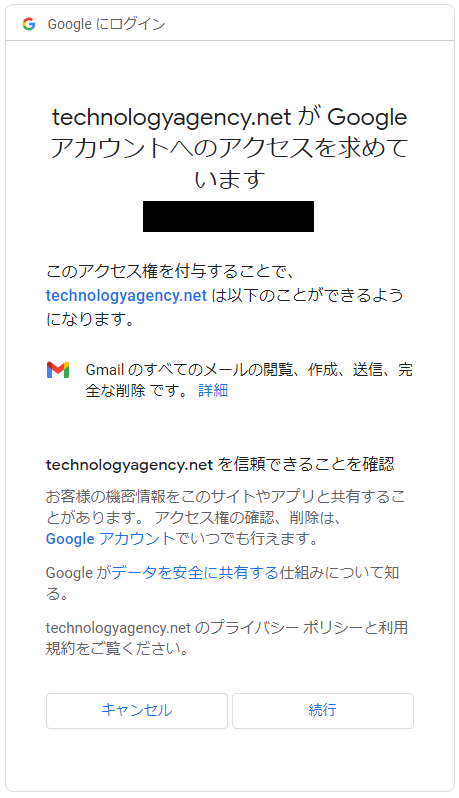
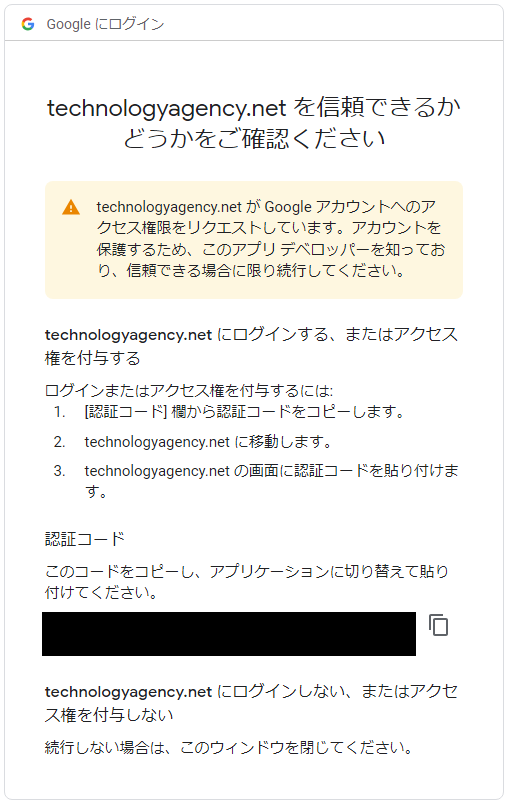
注意
Microsoft Exchangeのアカウント(例:@の後ろが企業名とか独自のドメインになっているもの)でないとSMTPのOAuth認証を有効に出来ないような。アカウント持っていないので詳細はわからない。
個人アカウントでも、Microsoft Entraでアプリの登録が出来るので、トークン取得部分だけ動作確認した。Microsoft Exchangeのアカウントがあれば、通しでも多分動くはず。
build.gradle
plugins {
id 'java'
}
group = 'oauth2hotmail'
version = '0.0.1-SNAPSHOT'
java {
sourceCompatibility = '17'
}
configurations {
compileOnly {
extendsFrom annotationProcessor
}
}
repositories {
mavenCentral()
}
dependencies {
implementation 'com.microsoft.azure:msal4j:1.14.2'
implementation 'com.sun.mail:jakarta.mail:2.0.1'
}
tasks.named('test') {
useJUnitPlatform()
}HotmailOAuth.java
public class HotmailOAuth {
private static final String SCOPE = "https://graph.microsoft.com/.default";
// アプリケーション(クライアント) ID
private static final String CLIENT_ID = "";
// クライアント シークレット
private static final String CLIENT_SECRET = "";
// OAuth 2.0 トークン エンドポイント (v2)
private static final String AUTHORITY = "https://login.microsoftonline.com/ディレクトリ(テナント) ID/oauth2/v2.0/token";
private static final String MAIL_FROM = "sender@foo.bar";
private static final String MAIL_TO = "receiver@foo.bar";
public static void main(String[] args) throws MalformedURLException, AddressException, MessagingException {
// アクセス トークンを取得
var token = getAccessTokenFromSecret();
// SMTP セッションを作成
var props = new Properties();
props.put("mail.smtp.host", "それぞれのSMTPホスト名");
props.put("mail.smtp.port", "587");
props.put("mail.smtp.auth", "true");
props.put("mail.smtp.auth.mechanisms", "XOAUTH2");
props.put("mail.smtp.starttls.enable", "true");
var session = Session.getDefaultInstance(props);
// メールを作成
var message = new MimeMessage(session);
message.setFrom(new InternetAddress(MAIL_FROM));
message.setRecipient(Message.RecipientType.TO, new InternetAddress(MAIL_TO));
message.setSubject("OAuth 2.0認証を使って送信したメール");
message.setText("このメールは、OAuth 2.0 認証を使って送信しました。");
// メールを送信
var transport = session.getTransport("smtp");
transport.connect(MAIL_FROM, token);
transport.sendMessage(message, message.getAllRecipients());
transport.close();
System.out.println("メールを送信しました。");
}
public static String getAccessTokenFromSecret() throws MalformedURLException {
var credential = ClientCredentialFactory.createFromSecret(CLIENT_SECRET);
var cca = ConfidentialClientApplication
.builder(CLIENT_ID, credential)
.authority(AUTHORITY)
.build();
var parameters = ClientCredentialParameters
.builder(Set.of(SCOPE))
.build();
var result = cca.acquireToken(parameters).join();
return result.accessToken();
}
}