1.やりたいこと
AWSの無料利用枠を利用して、Wordpress環境を構築し、インターネットに公開する。
2.AWSのアカウント作成
メールアドレスと、クレジットカードが必要になるため、事前に用意しておく。メールアドレスはフリーのアドレスで大丈夫だった。
下記の「無料アカウントを作成」をクリックし、指示通り入力を進める。
https://aws.amazon.com/jp/free/
3.Wordpressの実行に必要なもの
- Linuxサーバー
- apache(Wordpressをインストールする)
- mysql(Wordpressの記事を保存する)
Linuxサーバーの構築
Amazon Elastic Compute Cloud (Amazon EC2) はアカウント登録から12か月無料でサーバーを借りることが出来る。「無料利用枠の対象」と表記のあるLinuxサーバーであればどれでもよい。
最初の設定は全てデフォルトで良いが、セキュリティグループの設定でSSHによるアクセスを許可する場合は、警告文にある通りアクセスを制限することを検討したほうが良い。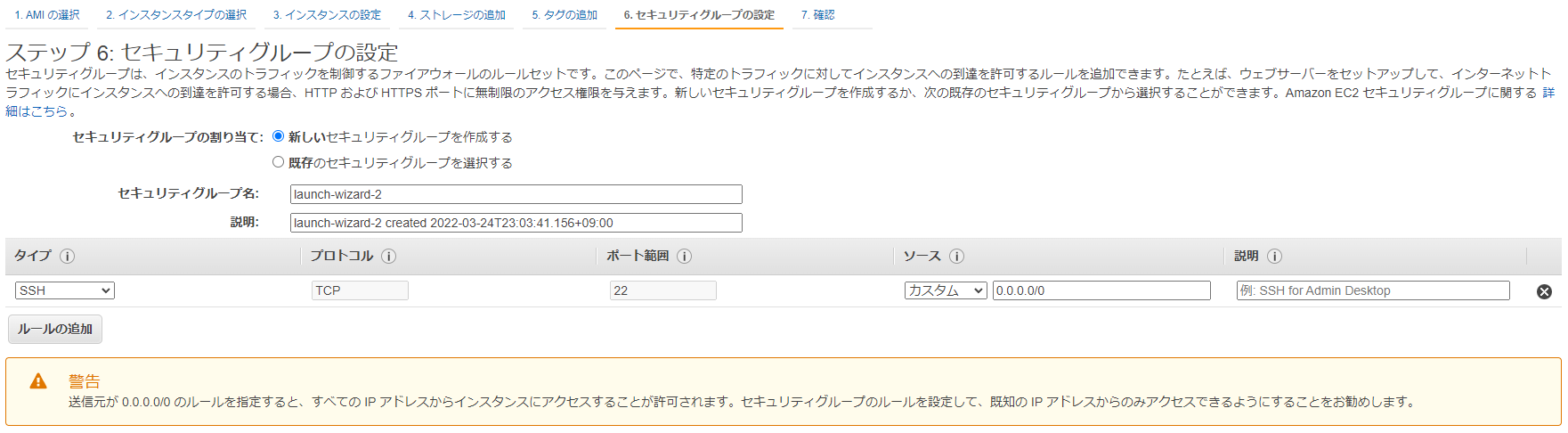
最後に画面の指示通りにSSHでアクセスするためのキーペアを作成する。これはSSHで接続するとき必要になるため、作成後必ずダウンロードしておく。
apache、phpのインストールと設定
sudo apt install apache2
sudo a2enmod rewrite
sudo a2enmod ssl
sudo a2ensite default-ssl
sudo apt install php libapache2-mod-php
sudo apt install php-fpm php-common php-mbstring php-xmlrpc php-gd php-xml php-mysql php-cli php-zip php-curl php-imagick
WordPressのパーマリンクに日付と投稿名を使用するため、.htaccessによる設定の上書きを有効にする。下記の通り、httpd.confのAllowOverrideをallに変更する。
<Directory /var/www/>
Options Indexes FollowSymLinks
AllowOverride all
Require all granted
</Directory>
設定を有効にするため、apacheを再起動する。
sudo service apache2 restart
DBサーバーの追加
Amazon RDSを使用する。こちらも無料利用枠があるのでMariaDBを選択した。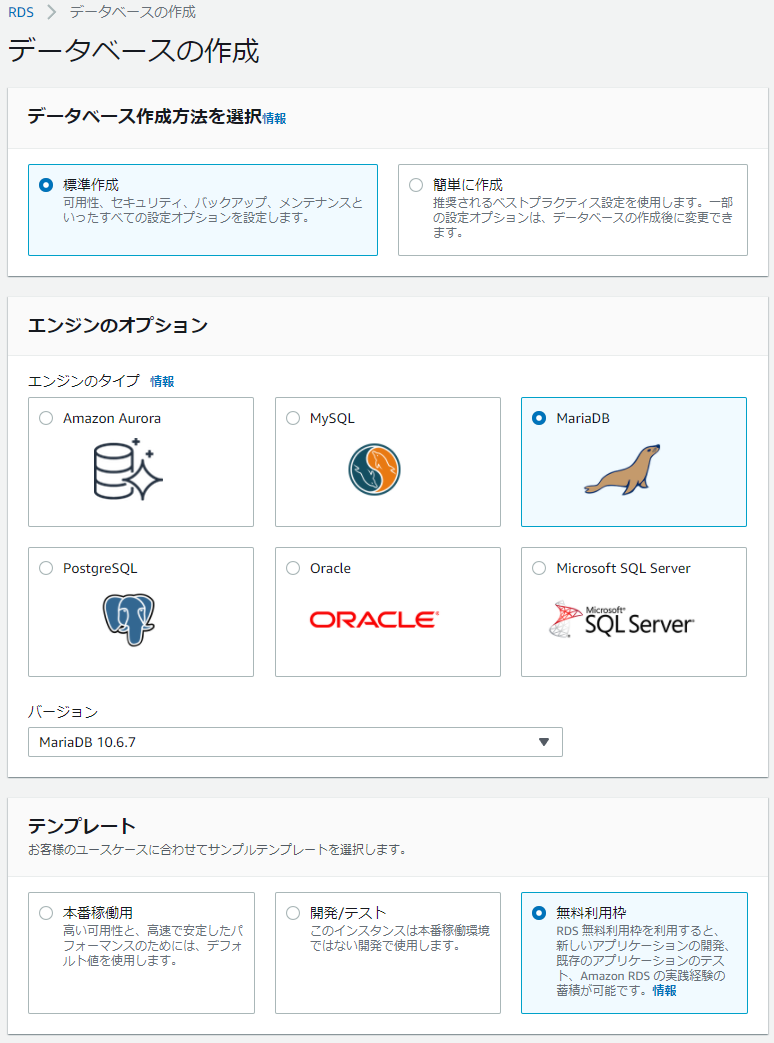
DBインスタンス識別子はわかりやすいように変更しておく。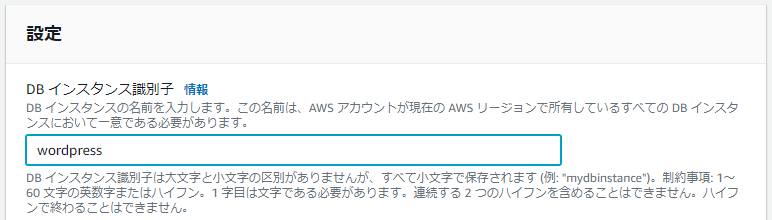
追加設定を開き最初のデータベース名を入力する。これを設定しておくと環境構築時にデータベースの作成まで行ってくれる。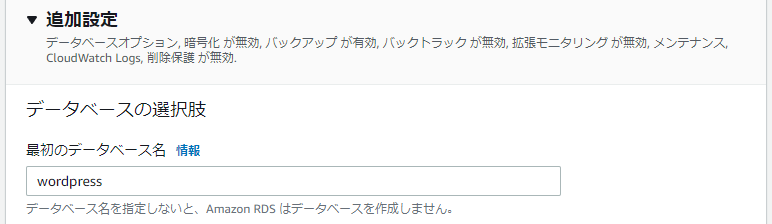
データベースの作成には少々時間がかかるので、気長に待つ。その間にデータベース用のセキュリティグループを作成する。
セキュリティグループの作成
セキュリティグループのインバウンドルールにMysqlの許可を追加する。外部からアクセスさせる必要はないので、ソースに先ほど作成したEC2のセキュリティグループを指定して、EC2サーバーからのみアクセス出来るように制限する。
データベースの作成とセキュリティグループの設定が終わったら、両者を忘れずに紐付る。
4.Wordpressのインストール
作成したEc2サーバーからAmazon RDSにアクセスし、Wordpressデータベースアクセス用のユーザを作成する。
export MYSQL_HOST=wordpress.作成したAmazon RDSのエンドポイント参照.rds.amazonaws.com
mysql -u ユーザー名 -p wordpress
CREATE USER 'wordpress' IDENTIFIED BY 'パスワード';
GRANT SELECT, UPDATE, DELETE, INSERT, CREATE, DROP, INDEX, ALTER, LOCK TABLES, EXECUTE, CREATE TEMPORARY TABLES, TRIGGER, CREATE VIEW, SHOW VIEW, EVENT ON wordpress.* TO wordpress;
FLUSH PRIVILEGES;
WordPressはダウンロードして、解凍するだけで良い。
5.動作確認
一時的にEC2にアクセス出来るようにする。先ほど作成したEC2サーバーのセキュリティグループを選択し、インバウンドルールの編集から80ポートのアクセス許可を追加する。
アクセスに必要なパブリックIPやDNSはインスタンス概要に記載がある。
今回はここまで。Wordpressを動かすだけであれば、これだけで良いが、本番運用するには、まだいくつか設定が必要になる。