小説を読もうの累計ランキングをDoc2Vecで解析する その3の続き。
今回はこれまで解析した特徴を表にプロットして可視化してみる。2次元の表にプロットするために、t-SNEを使用し次元を削減する。
t-SNEによる次元圧縮
import numpy as np
import matplotlib.pyplot as plt
from gensim.models.doc2vec import Doc2Vec
from sklearn.manifold import TSNE
# 学習済みモデルを読み込む
m = Doc2Vec.load('drive/My Drive/Colab Notebooks/syosetu/doc2vec.model')
weights = []
for i in range(0, len(m.docvecs)):
weights.append(m.docvecs[i].tolist())
weights_tuple = tuple(weights)
X = np.vstack(weights_tuple)
# t-SNEで次元圧縮する
tsne_model = TSNE(n_components=2, random_state=0, verbose=2)
np.set_printoptions(suppress=True)
t_sne = tsne_model.fit_transform(X)
# クラスタリング済みのデータを読み込む
with open('drive/My Drive/Colab Notebooks/syosetu/novel_cluster.csv', 'r') as f:
reader = csv.reader(f)
clustered = np.array([row for row in reader])
clustered = clustered.astype(np.dtype(int).type)
clustered = clustered[np.argsort(clustered[:, 0])]
clustered = clustered.T[1]
# グラフ描画
fig, ax = plt.subplots(figsize=(10, 10), facecolor='w', edgecolor='k')
# Set Color map
cmap = plt.get_cmap('Dark2')
for i in range(t_sne.shape[0]):
cval = cmap(clustered[i] / 4)
ax.scatter(t_sne[i][0], t_sne[i][1], marker='.', color=cval)
ax.annotate(i, xy=(t_sne[i][0], t_sne[i][1]), color=cval)
plt.show()
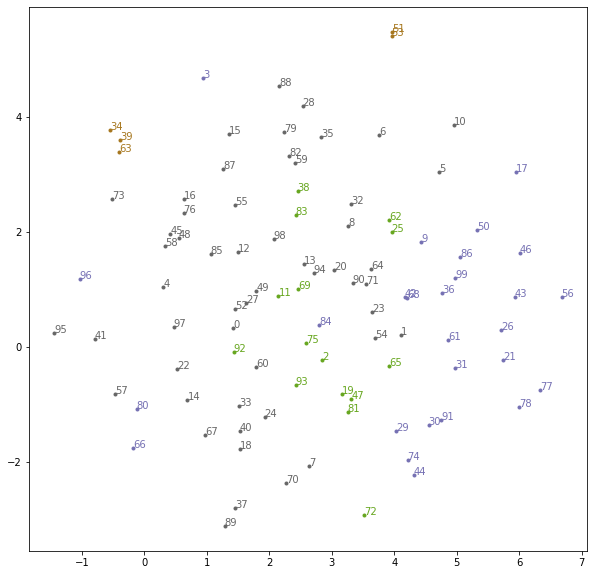
実行すると以下のようなグラフになった。満遍なく分布しているが同じクラスターの小説についてはある程度まとまって分布しているように見える。
続いて3次元のグラフを描画してくれる良いページがあるので使ってみる。
Embedding projector – visualization of high-dimensional data
上記のサイトで次元圧縮を行ってくれるので、こちらはTSV形式のデータを用意するだけで良い。
!pip install gensim torch tensorboardX
from torch import FloatTensor
from gensim.models import KeyedVectors
from tensorboardX import SummaryWriter
m = KeyedVectors.load('drive/My Drive/Colab Notebooks/syosetu/doc2vec.model')
weights = []
labels = []
for i in range(0, len(m.docvecs)):
weights.append(m.docvecs[i].tolist())
labels.append(m.docvecs.index_to_doctag(i))
# DEBUG: visualize vectors up to 1000
weights = weights[:1000]
labels = labels[:1000]
writer = SummaryWriter()
writer.add_embedding(FloatTensor(weights), metadata=labels)
実行すると「/content/runs/実行日付等/00000/default」にtensors.tsvとmetadata.tsvファイルが保存される。このファイルをEmbedding Projectorのページにアップロードする。
このままではどの点がどの小説を表しているかわかりずらいので、metadata.tsvを加工してタイトルが表示されるようにする。
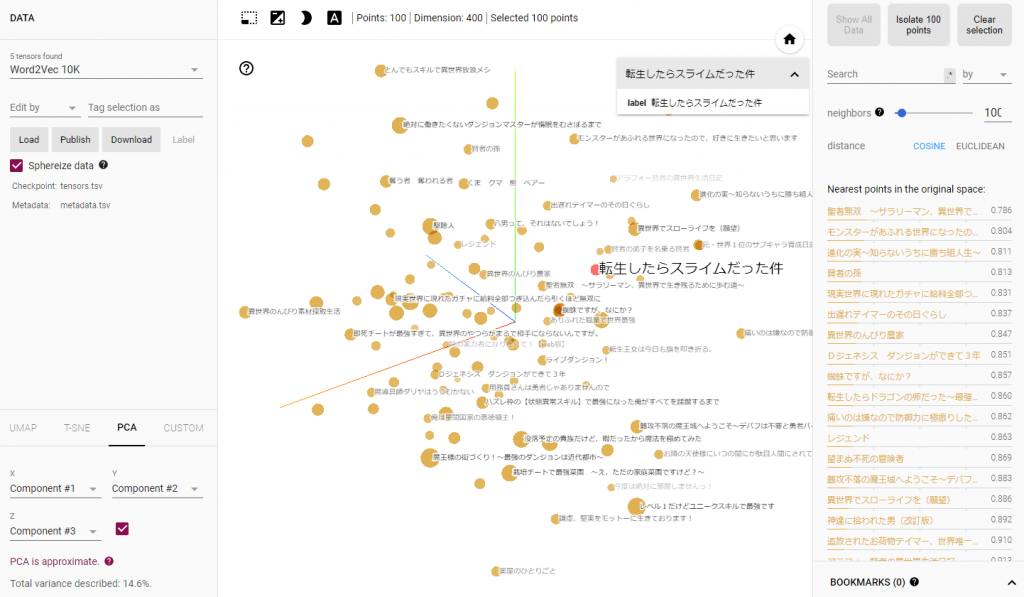
とても見やすいけれども、第1から第3主成分までの累積寄与率が14%ほどしかないので、PCAにて次元圧縮したこのグラフは残念ながら殆どあてにならない。PCA以外にも先ほど使用したt-SNEを使用することも可能。
まとめ
もう少しきれいなグラフが描けるように、ライブラリの使い方から勉強しなおす。