Recommendation Systemを考える2の続き。
1.やりたいこと
投稿されて間もない小説はユーザーによる評価がされていない場合が多いため、初期の評価ポイントはその小説の本来のおもしろさを反映していないと思われる。
小説の内容を機械学習で評価して、今後付くであろう評価ポイントを予測する。
最終的には新規投稿された小説、もしくは評価受付設定offになっている小説から評価ポイントが高くなると予想される小説を抽出するプログラムを作成する。
2.小説のスクレイピング
これまでの方法は累積ランキングから小説をダウンロードするため、Top300までしか小説を参照出来なかった。そのため、常にデータが不足していた。今回は方法を変えて小説検索画面から小説を参照するためのURL一覧を作成する。
まずは「小説を読もう!」の検索画面のURLを生成し、検索結果一覧を取得する。検索結果一覧は1ページあたり20リンクあり、最大100ページまで遡って表示する事ができる。その取得した結果をテキストファイルに書き出しておく。
import requests
import socket
from bs4 import BeautifulSoup
from pathlib import Path
from urllib.error import HTTPError, URLError
from time import sleep
from tqdm import tqdm
REQUEST_HEADERS = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
REQUEST_TIMEOUT = 20
SEARCH_URL = 'https://yomou.syosetu.com/search.php'
NOVEL_SEARCH_RESULT_PATH = str(Path.home()) + '/vscode/syosetu/data/search_novels.txt'
# 小説を検索してダウンロード
def novel_search_dler(max_search_page=100, max_search_result=20):
with open(NOVEL_SEARCH_RESULT_PATH, 'w') as f:
for page in tqdm(range(max_search_page)):
#search_params = {'word': '', 'type': 're', 'order_former': 'search', 'order': 'new', 'notnizi': '1', 'minlen': '5000', 'min_globalpoint': '1000', 'p': page + 1}
search_params = {'word': '', 'type': 're', 'order_former': 'search', 'order': 'hyoka', 'notnizi': '1', 'minlen': '5000', 'min_globalpoint': '1000', 'p': page + 1}
r = requests.get(SEARCH_URL, headers=REQUEST_HEADERS, timeout=REQUEST_TIMEOUT, params=search_params)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, 'html.parser')
sleep(1)
search_result = soup.find_all('div', class_='searchkekka_box')
for r_count in range(max_search_result):
a_list = search_result[r_count].find_all('a', limit=3)
url = a_list[0].get('href')
info_url = a_list[2].get('href')
title = a_list[0].get_text()
# 小説のURL、小説情報のURLと小説のタイトルを設定
f.write('{0}\t{1}\t{2}\n'.format(url, info_url, title))
print('url: {0} info_url: {1} title: {2}'.format(url, info_url, title))
novel_search_dler()
続いて先程作成した検索結果を順番に読み込み、小説の内容と評価ポイントを取得する。※morphologicalAnalysisのコードはmecab設定のページに記載。
import morphologicalAnalysis as ma
import requests
import socket
import pandas as pd
from bs4 import BeautifulSoup
from pathlib import Path
from urllib.error import HTTPError, URLError
from time import sleep
from tqdm import tqdm
REQUEST_HEADERS = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko'
}
REQUEST_TIMEOUT = 60
SCRAP_WORD = 5000
SCRAP_CHAPTER = 40
COL_NAMES = ['URL', 'INFO_URL', 'TITLE']
NOVEL_SEARCH_RESULT_PATH = str(Path.home()) + '/vscode/syosetu/data/search_novels.txt'
NOVEL_SEARCH_RESULT_DATA_PATH = str(Path.home()) + '/vscode/syosetu/data/search_novel_datas.txt'
# 小説情報をダウンロード
def novel_info_dler(url):
KEYWORD = 2
EVALUATION = 6
r = requests.get(url, headers=REQUEST_HEADERS, timeout=REQUEST_TIMEOUT)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, 'html.parser')
sleep(1)
keyword = soup.find(id='noveltable1').find_all('td')[KEYWORD].get_text(strip=True)
evaluation = soup.find(id='noveltable2').find_all('td')[EVALUATION].get_text(strip=True).replace('pt', '')
return keyword,evaluation
# 本文をダウンロード
def novel_text_dler(url):
r = requests.get(url, headers=REQUEST_HEADERS, timeout=REQUEST_TIMEOUT)
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, 'html.parser')
sleep(1)
novel_text = ''
# 章のタイトルに「設定」、「登場人物」が含まれる場合、戻り値は''とする
subtitle = soup.find('p', class_='novel_subtitle')
if subtitle is None or '設定' in subtitle or '登場人物' in subtitle:
return novel_text
honbun = soup.find_all('div', class_='novel_view')
for text in honbun:
novel_text += text.text.replace('\n', ' ') # 改行コードをスペースに変換
return novel_text
# 小説の各話をダウンロード
def novel_chapter_dler(url, scrap_word=SCRAP_WORD, scrap_chapter=SCRAP_CHAPTER):
chapter = 0
word_count = 0
total_words = ''
while word_count < scrap_word and chapter < scrap_chapter:
# 単語がscrap_word未満かつ、scrap_chapter話以下の間繰り返し取得する
try:
words = novel_text_dler('{0}{1}/'.format(url, chapter + 1))
except (HTTPError, URLError) as e:
print(e)
break
except socket.timeout as e:
print(e)
continue
else:
#print('chapter:{0}'.format(chapter + 1))
word_count += len(ma.analysis(words).split())
total_words += words
chapter += 1
return total_words
# 小説の検索結果をもとにダウンロード
def novel_search_data_dler():
df = pd.read_table(NOVEL_SEARCH_RESULT_PATH, header=None, names=COL_NAMES)
with open(NOVEL_SEARCH_RESULT_DATA_PATH, 'w') as f:
for index,item in tqdm(df.iterrows()):
url = item[COL_NAMES[0]]
info_url = item[COL_NAMES[1]]
title = item[COL_NAMES[2]]
keyword,evaluation = novel_info_dler(info_url)
# URL、小説のタイトル、キーワードと評価ポイントを設定
f.write('{0}\t{1}\t{2}\t{3}\t'.format(url, title, keyword, evaluation))
#print('url:{0} title:{1} keywords:{2} evaluation:{3}'.format(url, title, keyword, evaluation))
# 小説の各話を設定
f.write(novel_chapter_dler(url))
f.write('\n')
novel_search_data_dler()
サーバーに負荷をかけないようにするため、ページの取得に1秒のインターバルをおいているため、全ての取得には7時間ほどかかる。
3.回帰分析
良い結果は得られていないが、せっかくなので回帰分析するところまでのソースコードを公開する。評価ポイントを5段階くらいに分けて分類したほうが良い結果になると思う。
データを読み込む
Doc2Vecデータを読み込み、配列に変換する。
from gensim.models.doc2vec import Doc2Vec
from pathlib import Path
MODEL_DATA_PATH = str(Path.home()) + '/vscode/syosetu/data/search_novel_doc2vec_100.model'
m = Doc2Vec.load(MODEL_DATA_PATH)
vectors_list = [m.dv[n] for n in range(len(m.dv))]
データ処理しやすいように、必要な情報をPandasにまとめる。
import pandas as pd
import numpy as np
MODEL_TITLES_CSV_PATH = str(Path.home()) + '/vscode/syosetu/data/search_novel_titles.csv'
df = pd.read_csv(MODEL_TITLES_CSV_PATH, thousands=',')
df = df.drop(columns=['URL'])
df['VECTORS'] = vectors_list
Doc2Vecのデータをそのまま使うと次元数が大きすぎるので、PCAを使って次元圧縮する。
from sklearn.decomposition import PCA
def dimension_reduction(data, pca_dimension=20):
pca_data = data.copy()
pca = PCA(n_components=pca_dimension)
vector = np.array([np.array(v) for v in pca_data['VECTORS']])
pca_vectors = pca.fit_transform(vector)
pca_data['PCA_VECTORS'] = [v for v in pca_vectors]
return pca_data
df = dimension_reduction(data=df)
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2000 entries, 0 to 1999
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 TITLE 2000 non-null object
1 KEYWORDS 2000 non-null object
2 EVALUATION 2000 non-null object
3 VECTORS 2000 non-null object
4 PCA_VECTORS 2000 non-null object
dtypes: object(5)
memory usage: 78.2+ KB
不要な文字を取り除き、数値に変換する。
df['EVALUATION'] = df['EVALUATION'].str.replace(',', '')
df['EVALUATION'] = df['EVALUATION'].str.replace('評価受付停止中', '').astype(float)
df['EVALUATION'].describe()
count 2000.000000
mean 32735.061500
std 33540.729876
min 4019.000000
25% 14118.000000
50% 21271.000000
75% 38219.250000
max 323929.000000
Name: EVALUATION, dtype: float64
トレーニングデータとテストデータに分ける。
from sklearn.model_selection import train_test_split
X = pd.DataFrame(df['PCA_VECTORS'].tolist(), index=df.index)
X.columns = [f'No{i+1}' for i in range(len(X.columns))]
y = df['EVALUATION']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
データを確認する
必要なライブラリをインポートしておく。
from scipy import stats
from scipy.stats import norm, skew # for some statistics
# visualization
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
color = sns.color_palette()
sns.set_style('darkgrid')
import warnings
def ignore_warn(*args, **kwargs):
pass
warnings.warn = ignore_warn # Ignore annoying warning (from sklearn and seaborn)
評価ポイントの分布を可視化する。
sns.distplot(y_train, fit=norm)
# Get the fitted parameters used by the function
(mu, sigma) = norm.fit(y_train)
print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))
# Now plot the distribution
plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],
loc='best')
plt.ylabel('Frequency')
plt.title('Evaluation distribution')
# Get also the QQ-plot
fig = plt.figure()
res = stats.probplot(y_train, plot=plt)
plt.show()
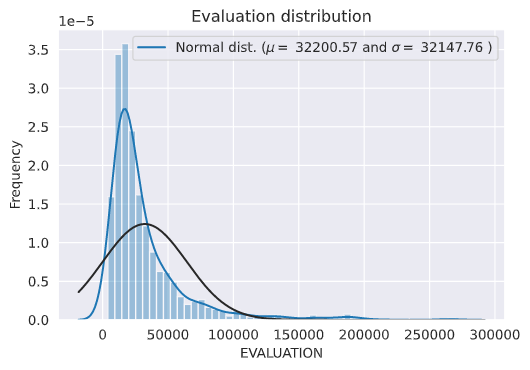
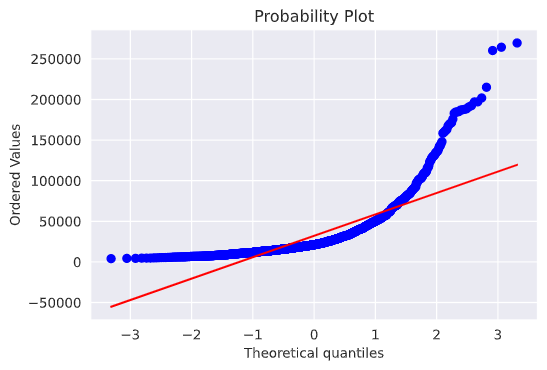
だいぶ歪んだ分布をしているので、対数変換を行う。
# We use the numpy fuction log1p which applies log(1+x) to all elements of the column
y_train = np.log1p(y_train)
# Check the new distribution
sns.distplot(y_train, fit=norm)
# Get the fitted parameters used by the function
(mu, sigma) = norm.fit(y_train)
print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))
# Now plot the distribution
plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],
loc='best')
plt.ylabel('Frequency')
plt.title('Evaluation distribution')
# Get also the QQ-plot
fig = plt.figure()
res = stats.probplot(y_train, plot=plt)
plt.show()
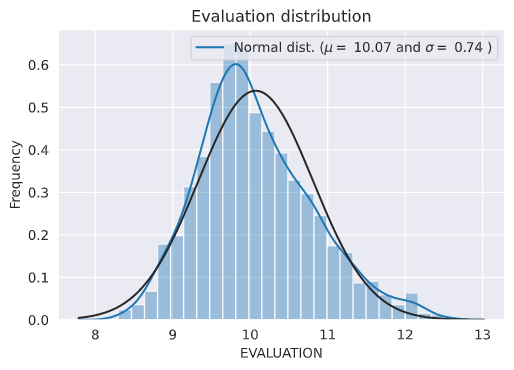
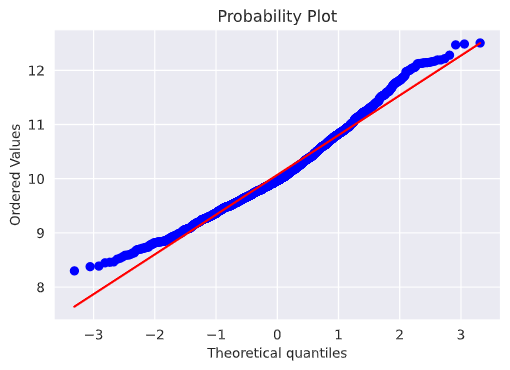
作成したデータを元に予測する
Lassoで回帰分析を実施する。
from sklearn.model_selection import cross_val_score, KFold
kf = KFold(5, shuffle=True, random_state=0).get_n_splits(X_train)
# Validation function
def rmsle_cv(classifier):
return np.sqrt(-cross_val_score(classifier, X_train.values, y_train.values, scoring="neg_mean_squared_error", cv=kf))
from sklearn.linear_model import Lasso
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import RobustScaler
lasso = make_pipeline(RobustScaler(), Lasso(random_state=0))
score = rmsle_cv(lasso)
print("Lasso score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
Lasso score: 0.7408 (0.0095)
4.まとめ
今回はやりたいことが出来なかったため、前述した通り分類問題で改めて分析してみる。