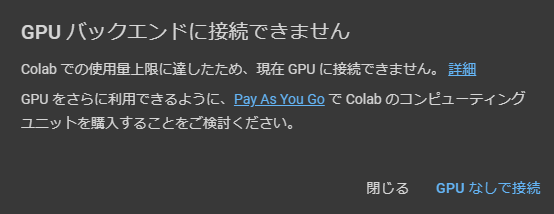
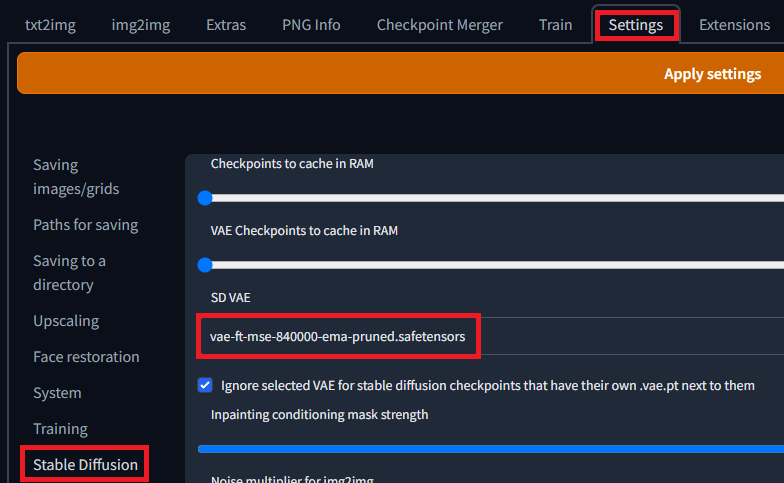
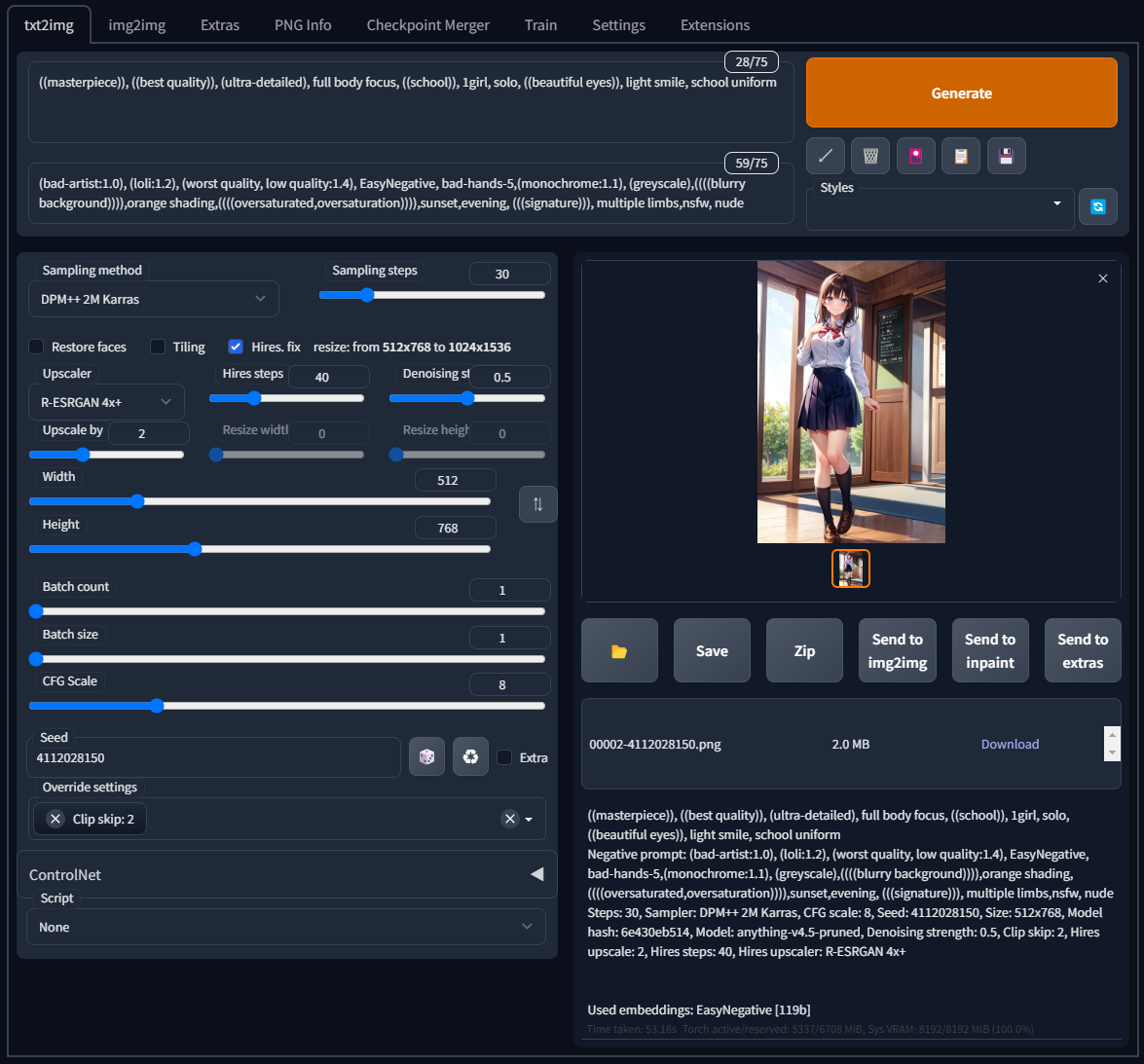
Stable Diffusion web UIだけでは画像を出力することは出来ない。様々な画像を学習させて作成した「model」が必要になる。「model」の種類によってアニメ系が得意、リアル系が得意、背景が得意など色々あるが、今回は下記のアニメ系が得意なモデルをダウンロードする。画像を出力して気に入らなければ、別のモデルを探せば良い。
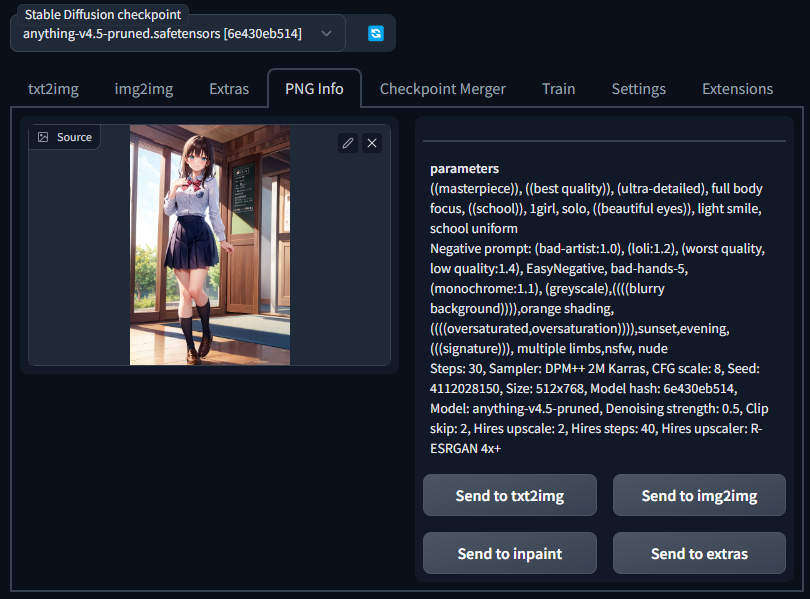
そこで、PNG Infoタブの機能を使用する。このSource欄にStable Diffusion web UIによって出力された画像をドラッグアンドドロップすると、その画像を出力したときのPromptを見ることが出来る。Promptが表示されたらSend to txt2imgをクリックすることで内容をコピーすることが出来る。
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=True)
prompt = "a photograph of an astronaut riding a horse"
image = pipe(prompt)["sample"][0]
image.save("horse.png")
image
Windows 11 WLS2 Ubuntu 20.04 Python 3.8.10 cuda-toolkit-11-6 is already the newest version (11.6.2-1). libnccl-dev is already the newest version (2.12.10-1+cuda11.6). libcudnn8 is already the newest version (8.4.0.27-1+cuda11.6). VSCODE 1.66.2
cmake is already the newest version (3.16.3-1ubuntu1). espeak is already the newest version (1.48.04+dfsg-8build1). torch in ./.local/lib/python3.8/site-packages (1.11.0+cu113) torchvision in ./.local/lib/python3.8/site-packages (0.12.0+cu113) torchaudio in ./.local/lib/python3.8/site-packages (0.11.0+cu113) pyopenjtalk in ./.local/lib/python3.8/site-packages (0.2.0)
Cython in ./.local/lib/python3.8/site-packages (0.29.28) librosa in ./.local/lib/python3.8/site-packages (0.9.1) matplotlib in ./.local/lib/python3.8/site-packages (3.5.2) numpy in ./.local/lib/python3.8/site-packages (1.21.6) phonemizer in ./.local/lib/python3.8/site-packages (3.1.1) scipy in ./.local/lib/python3.8/site-packages (1.8.0) tensorboard in ./.local/lib/python3.8/site-packages (2.8.0) Unidecode in ./.local/lib/python3.8/site-packages (1.3.4) retry in ./.local/lib/python3.8/site-packages (0.9.2) tqdm in ./.local/lib/python3.8/site-packages (4.64.0)
from gensim.models.doc2vec import Doc2Vec
from pathlib import Path
MODEL_DATA_PATH = str(Path.home()) + '/vscode/syosetu/data/search_novel_doc2vec_100.model'
m = Doc2Vec.load(MODEL_DATA_PATH)
vectors_list = [m.dv[n] for n in range(len(m.dv))]
from sklearn.model_selection import train_test_split
X = pd.DataFrame(df['VECTORS'].tolist(), index=df.index)
X.columns = [f'No{i+1}' for i in range(len(X.columns))]
y = df['EVALUATION']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
from gensim.models.doc2vec import Doc2Vec
from pathlib import Path
MODEL_DATA_PATH = str(Path.home()) + '/vscode/syosetu/data/search_novel_doc2vec_100.model'
m = Doc2Vec.load(MODEL_DATA_PATH)
vectors_list = [m.dv[n] for n in range(len(m.dv))]
from sklearn.decomposition import PCA
def dimension_reduction(data, pca_dimension=20):
pca_data = data.copy()
pca = PCA(n_components=pca_dimension)
vector = np.array([np.array(v) for v in pca_data['VECTORS']])
pca_vectors = pca.fit_transform(vector)
pca_data['PCA_VECTORS'] = [v for v in pca_vectors]
return pca_data
df = dimension_reduction(data=df)
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2000 entries, 0 to 1999
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 TITLE 2000 non-null object
1 KEYWORDS 2000 non-null object
2 EVALUATION 2000 non-null object
3 VECTORS 2000 non-null object
4 PCA_VECTORS 2000 non-null object
dtypes: object(5)
memory usage: 78.2+ KB
不要な文字を取り除き、数値に変換する。
df['EVALUATION'] = df['EVALUATION'].str.replace(',', '')
df['EVALUATION'] = df['EVALUATION'].str.replace('評価受付停止中', '').astype(float)
df['EVALUATION'].describe()
count 2000.000000
mean 32735.061500
std 33540.729876
min 4019.000000
25% 14118.000000
50% 21271.000000
75% 38219.250000
max 323929.000000
Name: EVALUATION, dtype: float64
トレーニングデータとテストデータに分ける。
from sklearn.model_selection import train_test_split
X = pd.DataFrame(df['PCA_VECTORS'].tolist(), index=df.index)
X.columns = [f'No{i+1}' for i in range(len(X.columns))]
y = df['EVALUATION']
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
データを確認する
必要なライブラリをインポートしておく。
from scipy import stats
from scipy.stats import norm, skew # for some statistics
# visualization
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
color = sns.color_palette()
sns.set_style('darkgrid')
import warnings
def ignore_warn(*args, **kwargs):
pass
warnings.warn = ignore_warn # Ignore annoying warning (from sklearn and seaborn)
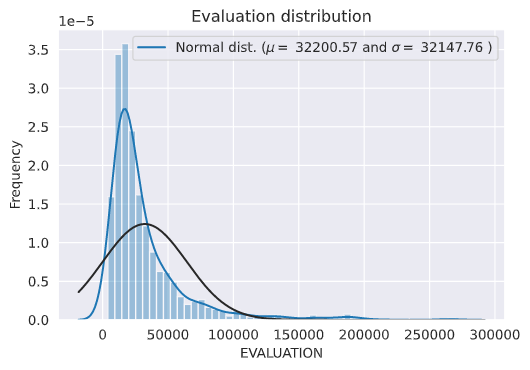
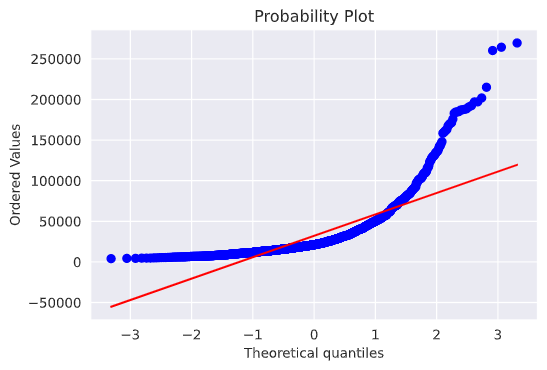
評価ポイントの分布を可視化する。
sns.distplot(y_train, fit=norm)
# Get the fitted parameters used by the function
(mu, sigma) = norm.fit(y_train)
print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))
# Now plot the distribution
plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],
loc='best')
plt.ylabel('Frequency')
plt.title('Evaluation distribution')
# Get also the QQ-plot
fig = plt.figure()
res = stats.probplot(y_train, plot=plt)
plt.show()
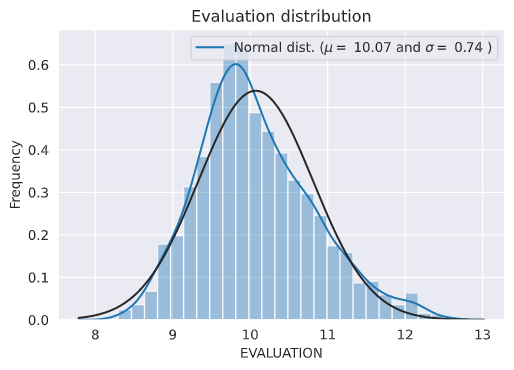
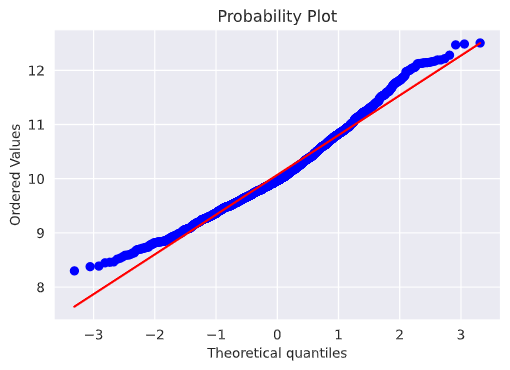
だいぶ歪んだ分布をしているので、対数変換を行う。
# We use the numpy fuction log1p which applies log(1+x) to all elements of the column
y_train = np.log1p(y_train)
# Check the new distribution
sns.distplot(y_train, fit=norm)
# Get the fitted parameters used by the function
(mu, sigma) = norm.fit(y_train)
print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))
# Now plot the distribution
plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],
loc='best')
plt.ylabel('Frequency')
plt.title('Evaluation distribution')
# Get also the QQ-plot
fig = plt.figure()
res = stats.probplot(y_train, plot=plt)
plt.show()
from sklearn.model_selection import train_test_split
X = train['vectors']
y = train['female']
X_array = np.array([np.array(v) for v in X])
y_array = np.array([i for i in y])
X_train, X_test, y_train, y_test = train_test_split(X_array, y_array, random_state=0)
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=-1, train_sizes=np.linspace(.1, 1.0, 5)):
'''Generate a simple plot of the test and training learning curve'''
plt.figure()
plt.title(title)
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel('Training examples')
plt.ylabel('Score')
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color='r')
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1,
color='g')
plt.plot(train_sizes, train_scores_mean, 'o-', color='r',
label='Training score')
plt.plot(train_sizes, test_scores_mean, 'o-', color='g',
label='Cross-validation score')
plt.legend(loc='best')
return plt
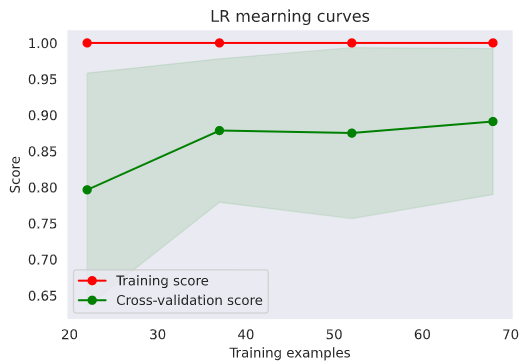
g = plot_learning_curve(gsLR.best_estimator_, 'LR mearning curves', X_train, y_train, cv=kfold)
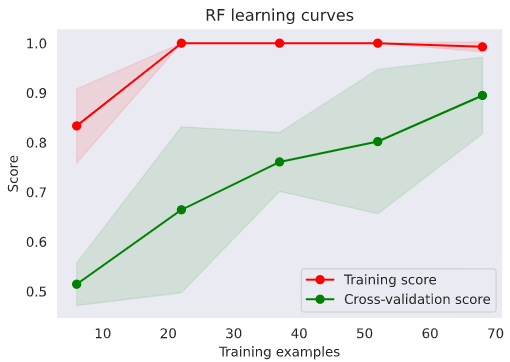
g = plot_learning_curve(gsRF.best_estimator_, 'RF learning curves', X_train, y_train, cv=kfold)
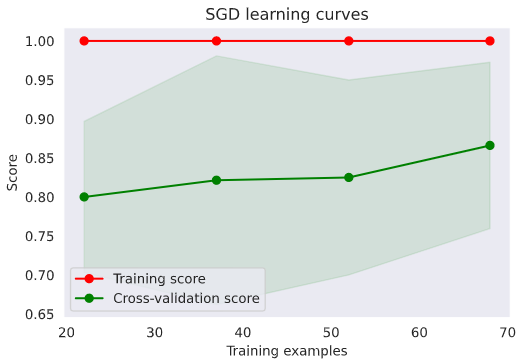
g = plot_learning_curve(gsSGD.best_estimator_, 'SGD learning curves', X_train, y_train, cv=kfold)
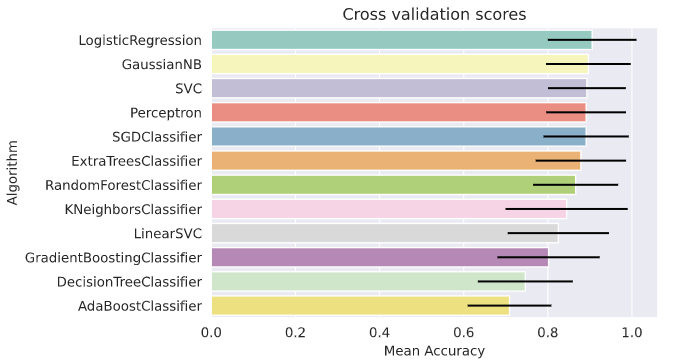
Random Forestも良い気がしてきた。何とかトレーニングデータを増やしてもう少し確認したい。
最後に
全くトレーニングで使用していない未知のデータに対して、 Random Forest の予測モデルで判定してみたところ83%程の正解率だった。なろう小説のTop300はファンタジー系の小説が多いため、ファンタジー系の小説において、この正解率とみた方が良いかも知れない。ジャンルが違う小説の場合どのような結果になるか現時点では予測不能である。
from gensim.models.doc2vec import Doc2Vec
MODEL_DATA_PATH = 'drive/My Drive/Colab Notebooks/syosetu/doc2vec_100.model'
m = Doc2Vec.load(MODEL_DATA_PATH)
vectors_list = [m.docvecs[n] for n in range(len(m.docvecs))]